Proceedings of the 2nd Workshop on Adaptive Hypertext and Hypermedia
HYPERTEXT'98, Pittsburgh, USA, June 20-24, 1998
Alberto Negro
Vittorio Scarano
Rosaria Simari
Dipartimento di Informatica ed Applicazioni
"R.M. Capocelli",
Università di Salerno
83025, Baronissi (Salerno), Italy
e-mail: {alberto |
vitsca}@dia.unisa.it
Abstract:
In this paper, we present some developments of CHEOPS , a package
that can be used by WWW designers to provide their hyperdocument
with adaptivity and navigational aids.
Previous version of CHEOPS , presented in (Ferrandino et al. 1997), is
implemented by several CGI-BIN scripts that enables an HTTP server
to interact with a user and adapt its responses to her behaviour.
Solution is transparent to the user and to the client, and has a
moderate impact on server performances.
What we present here is the extension of CHEOPS that takes into
account user modeling (i.e. extends adaptivity to multi-session
interactions) providing also annotations capability. The new version
of CHEOPS , named 1.0, is developed in PERL and is therefore more
portable.
We conclude by sketching future directions of CHEOPS and some
possible usage of the knowledge model in on-line help and training
systems.
Keywords: User Adaptivity on WWW, PERL, CGI-BIN
The World Wide Web (WWW), developed in 1989 at CERN as a means of
sharing information within the organization, is now an information
retrieval system on the Internet that can be considered the first real
global hypermedia network. The exponential growth of WWW has made it
the most visible service offered by the Internet and, therefore, has
attracted a variety of interests.
Among them, one of the most recognizable is the educational usage of
WWW. In fact, several educational systems based on WWW have been
developed in the recent past and many results are available on the
educational use of the Web for distance learning
[Dwyer et al. (1995),Hammond and Allison (1989),Ibrahim (1994),Ibrahim and Franklin (1995)].
In particular, in [Ibrahim (1994)] the need for a ``WWW work session''
(using our terminology) in an educational setting was recognized and
an application based on CGI-BIN programs was developed that adds a
similar capability to the Web server.
In order to fully exploit WWW potentiality in the educational field,
server response must be adaptive: it must, in fact be aware of user's
behaviour so that it can take into account the level of knowledge and,
as a consequence, provide the user with documents that she can read,
given her background/capacity.
Adaptive hypermedia is a recent research area whose goal is to enhance
the functionality of hypermedia by building a model of the user and
adapting the response accordingly[Brusilovsky (1996),Brusilovsky (1997)].
What we propose here is a system that is based on an ``opaque''
mechanism, that, based on the history of user's requests, can provide
a different document that is likely to be understood and lightly
challenging while not being intimidating. This can be useful also in
other contexts, i.e., avoiding that the large amount of information
available can scare a user off the site, since she can `` have
trouble in finding the information they need'' [Nielsen (1990)]
and, therefore, can loose interest in the site itself.
CHEOPS System
CHEOPS is oriented toward a ``server-side'', application-specific
solution to the adaptivity requirement, with particular care in
avoiding overloading the server with many tasks. Its architecture is
designed to limit concerns on users' privacy: the session that
CHEOPS keeps track of is strictly limited to the ``current''
hyperdocument and is not extended on user's behaviour on the whole Web
site. Moreover, CHEOPS , although specific to educational
application, can be also generalized to other similar situations when
presenting information at the right rate (for the user) is crucial.
CHEOPS is a design system that should make easy for a designer to
add adaptivity to a hyperdocument in a modular way. Especially with
the extensions described here and available in version
1.0, this goal looks quite reachable.
CHEOPS adopts the following strategy: each time a new user is
presented to the systems, the server creates a user's profile,
``distributing'' (virtually) a ``session card'' embedded within
the hypertext file that is sent back to the browser. Each
successive requests to the server will be done with this session card
and, therefore, recognized as belonging to a specific session.
The system is also able to recognize (by a username-password pairs)
users and recover the profile and the history for her.
CHEOPS system is non-obtrusive, widely usable, (one does not need
specific browsers to use our system), has moderate impact on server
load (putting all the ``memory'' of the session where it belongs, i.e.
on the disk) and is modular enough to be easily installed on a Web
server for a specific hyperdocument.
CHEOPS is implemented through several CGI-BIN PERL scripts, used to
build ``on-the-fly'' documents that depend on user's previous
inquiries at the same server. CGI-BIN scripts are program run on the
server and triggered by input from a browser.
CHEOPS is a ``server-side'' implementation of a session-based
interaction model based on several specifications required by an
educational, WWW-based, software.
The system, given a hyperdocument as HTML pages, is able to provide
the requested page to the user according to her profile that is
modified each time the user chooses a link. The system provides the
page adding additional information like links to context-sensitive
help, information about her current profile (given in terms of
knowledge levels for each category, details follow in the next
subsection), links to ``summaries'' for each category, a form to add
annotation to each visited page, link to the history of the visited
documents and so on.
CHEOPS version 0.9 (presented in [Ferrandino et al. (1997)]) consisted of several
Unix Shell scripts that provide the designer of a hyperdocument with
an automatic mechanism that satisfies user's requests according to
previous inquiries. The extension presented in this paper are mainly about
the user profiling mechanism and the annotation capability
that has been added to the system.
Analysis of requirements.
Being focussed on developing a design tool for hyperdocument to be
employed in the educational field, several requirements were
identified during preliminary experiences:
- Lecture-type Interaction: The user should be able to interact
with a WWW hyperdocument that makes her feel like having a
teacher/instructor/field-expert `` on the other side of the
screen''. To reach such a goal, it is necessary to have tools
able to distinguish between requests of different users. It is also
recommended the usage of context-sensitive help, where by context it
is not only meant the part of hyperdocument currently visited but
also the user knowledge and previous interactions with the help
system.
- Categories: It is often the case that there is a ``natural''
subdivision of the hyperdocument in categories that are well-suited
to the argument. It is important that user is able to check her
``knowledge level'' for each category and also able to choose to
further explore a category that, willingly or not, was ignored at a
previous step.
- History Mechanism and Annotations:
User should be able to check the path
followed during her interaction with the hyperdocument: being able
to trace back previous interactions with the comments to each single
visited page is extremely helpful in developing and reviewing the actions taken.
The Session Protocol.
The session protocol that has been implemented is based on the
following sequence of actions:
- Introduction. A new user is introducing herself to
the server through the choice of an ``introductory'' link. At this
time, the user can be recognized as an already known user and, in
this case, CHEOPS is able to recover the session
previously interrupted (see step 5). If the user is a new one, the
system is able to manage the request of a new user to enroll into
the system by asking her a username-password. pair.
- Beginning of the Session. When the user is known by
CHEOPS , the server responds by sending
the user a Session Card, that is a unique, opaque, identifier
that will be used in the following interactions by the client thus
identifying itself as ``known'' for the system.
- Session. An (unlimited) number of interactions user-server
where each action is accounted for and used by the server in order
to adapt its future responses to the same user.
- Interrupt the Session. The user is simply chosing a
different URL and leaves the system.
- Recovery of the Session. The user is resuming the
session and the system allows for recovery of information about the
user.
CHEOPS is based on the knowledge model, already presented in
[Ferrandino et al. (1997)]. Here we describe its motivations and characteristics.
When a hyperdocument is designed for a broad audience, it is customary
to face several problems in trying to make its style acceptable
for novices, amateurs and experts at the same time. They all have
different, some time opposite needs: a novice may need information
that can be boring for an expert since it makes her loose time in
finding the more advanced part of the hyperdocument. On the other
side, a novice can be scared and confused by an excessive usage of
technicality and leave the site before she could have the chance to
access information that are suitable for her experience in the field.
Then, great care must be taken to fulfill this important, we dare say
paramount, requirement if one is asked to use at its best such an
efficient communication media like the World Wide Web.
Another orthogonal need is to help the user (whichever level and
experience they have) in navigating through the (sometimes huge)
amount of information. This is often achieved by subdividing data in a
limited number of categories that can be seen as providing an
hypertext of a small degree of traditional linearity within the
hypertext itself.
Putting all together, the view we propose as a model for
dealing with the ``shapeless'' amount of information is a geometric
one: let us build a Knowledge Pyramid, having as bases two
regular polygons of the same shape but of different size, the smallest
on the top. Each vertex of the polygon represents one of the
categories which the designers subdivided the whole amount in; the
edges of the pyramid represents the experience level in each category.
The experience acquired by a user is defined as the surface obtained
interpolating the intersection of the current experience levels on
each category. The learning process can be seen as trying to get the
surface as low as possible.
A possible variation of the model can be to have fewer category on the
top than on the bottom. This corresponds to the natural mechanism to
avoid mentioning some categories if the user may not be ready and
actually may be disturbed by that.
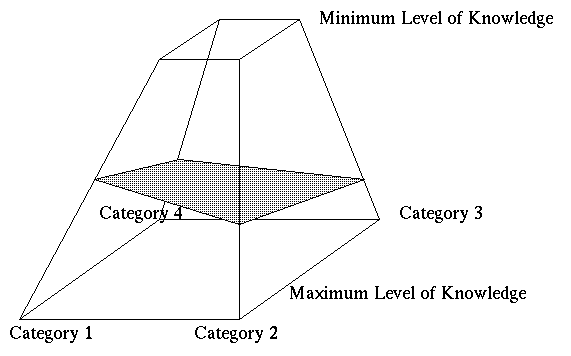
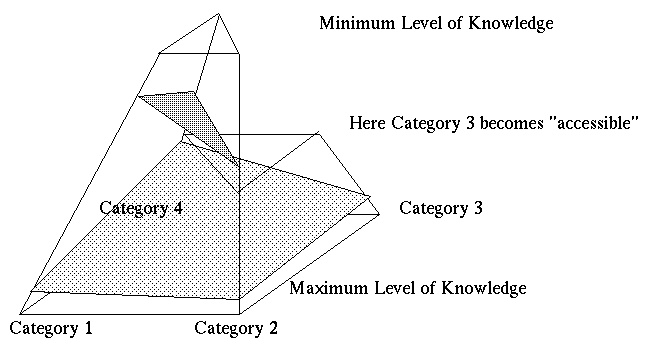
Figure 1: Top.
The Knowledge Pyramid: corners represent categories and
the surface is the ``current level'' of knowledge of the
subject.(full size)
Bottom. The Model when Category 3 is accessible only
given a certain knowledge of the subject.(full size)
CHEOPS uses the Knowledge Pyramid as an important navigational aid
to the user: at each step, the user is able to see what her confidence
for each category is (or is supposed to be by CHEOPS ) and act as a
consequence. She may choose to explore a part of the hyperdocument she
left behind, or she may want to go deeper in a category or she may go
on with her hypertextual visit of the document.
Here, we briefly describe how to use and the new capabilities
available in CHEOPS 1.0. More information about the package (and
the package itself) will soon be available at the URL
http://stromboli.dia.unisa.it/CHEOPS/.
The entire package has been moved from csh to a more portable
and powerful language as PERL. The system, moreover, uses Relational
Database System ([RDB]) for storing both users' profiles and
history information.
CHEOPS is designed taking into account the needs of designers:
not much additional work is required in order to make a hyperdocument
adaptive to user's responses. Once, CHEOPS is installed into the
CGI-BIN directory of the WWW server and the system is configured so
that every tool needed is available, the remaining tasks are as follows:
- Design the WWW hyperdocument as usual: HTML files with hyperlinks
pointing to other files within the whole hyperdocument.
- Categorize the files in categories with knowledge levels. Fix
the visibility of some categories.
- Edit the default configuration file general.dat provided with the
distribution. Insert all the information relevant to the
hyperdocument being designed as its directory, home page, the first
file to be shown, names of the categories and so on.
- Build the Category summaries that collect (in a domain-sepcific
way) links to all the documents at the same level for a given
category. Summaries are, usually, already been developed during the
usual design of the hyperdocument.
- Provide an entry point to the document as a call to particular
CGI-BIN script.
In this subsection we briefly describe the major extensions provided
in CHEOPS 1.0.
Annotations. CHEOPS 0.9 provided a history of the
interactions to the user. Now, the system allows the user to add
annotations to each visited page, by evaluating each page as ``Not
interesting'', ``Interesting'' and ``Very Interesting'' and by adding
a one-line comment. At this moment, annotations are visible only to
the user that wrote them. Future developments will allow to share
comments on pages.
Adaptive and Adaptable.
The system now fully allows the user to choose and modify the
knowledge levels. CHEOPS is, therefore, not only adaptive but also
adaptable, a characteristic that is very important for experienced users.
Categories. In this version, we have enhanced the way the
designer can choose to adapt CHEOPS to its domain-specific
application. In fact, while inCHEOPS 0.9 only a fixed number of categories were available,
in the new version the designer can choose the number of
categories as she likes. Moreover, and maybe even more important, the
designer can decide to have a multi-faceted pyramid: a category can
appear to the user only if a certain knowledge level on other
categories has been reached.
User modeling. The system is now able to keep the current
profile of each user in a DataBase so that it can be easily retrieved
in successive interactions. The system allows also (on a WWW server
Apache [Apache]) to insert and change password for users through
a fill-in form.
Removable Headers/Footers.
CHEOPS inserts header and footer for each page. Now the designer can
choose to provide or not headers/footers for each page while the user
at run-time can choose to turn headers/footers on and off.
The design of CHEOPS has been highly influenced by a project of an
hypertextual document on Theory of Music that, in fact, represents a
useful paradygm since the argument can be accessed both by a novice
and by an expert. Other experiences in using CHEOPS 1.0 have been
done in the field of Medical Information System for Stomach Illnesses
and have been deployed on a PC, using the portability of PERL.
We feel that the knowledge model introduce by CHEOPS can be very
helpful in fields that are only marginally related to ``pure'' educational
purposes as in Computer Based Training (CBT) systems or on-line help
and training systems.
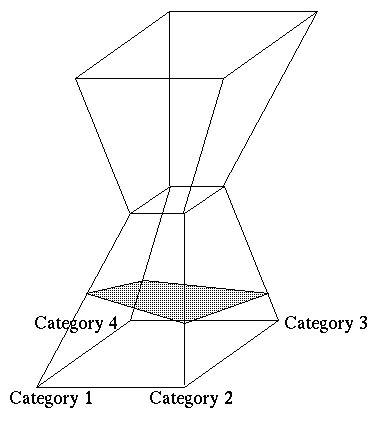 In this case, in fact, the CHEOPS knowledge model can be extended to
encompass two pyramids, a top one and a bottom one, connected as shown
at the left. The motivation is that, at beginning, the
trainee is in ``training'' process and, therefore, needs a lot of
information. When the trainee is sufficiently expert she does not need
such a huge amount of information and therefore, her profile is now
staying in the area between the bottom and the top pyramid. If
necessary, when some particular problem requires extremely specific
information, the trainee can go deeper and deeper and her profile
moves down to the bottom pyramid.
In this case, in fact, the CHEOPS knowledge model can be extended to
encompass two pyramids, a top one and a bottom one, connected as shown
at the left. The motivation is that, at beginning, the
trainee is in ``training'' process and, therefore, needs a lot of
information. When the trainee is sufficiently expert she does not need
such a huge amount of information and therefore, her profile is now
staying in the area between the bottom and the top pyramid. If
necessary, when some particular problem requires extremely specific
information, the trainee can go deeper and deeper and her profile
moves down to the bottom pyramid.
Future extensions of CHEOPS are, therefore related to such
applications. We plan to study the training process and develop
different knowledge models by providing, at the same time, a package
that allows to realize such adaptive systems on the World Wide
Web. Relevant future work include dealing with multiple user
annotations and providing adaptivity in a cooperative environment,
where different trainees collaborate over the learning process and are
seen by CHEOPS as a group of users that, as a whole, behave as a
unique user still mantaining personal peculiarities.
Moreover, research on authoring systems for CHEOPS is also planned.
References
- Apache
- ``WWW Server Apache''. http://www.apache.org.
- Brusilovsky (1996)
- P. Brusilovsky. ``Methods and
techniques of adaptive hypermedia''. User Modeling and User-Adapted
Interaction, 6 (2-3), pp. 87-129, 1996.
- Brusilovsky (1997)
- P. Brusilovsky. ``Efficient
techniques for adaptive hypermedia''. In: C. Nicholas and J.
Mayfield (eds.): Intelligent hypertext: Advanced techniques for the
World Wide Web. Lecture Notes in Computer Science, Vol. 1326,
Berlin: Springer-Verlag, pp. 12-30, 1997.
- Dwyer et al. (1995)
- D. Dwyer, K. Barbieri, H.M. Doerr. `` Creating
a Virtual Classroom for Interactive Education on the Web''. Proc.
of WWW 95, Third Int. Conf. on World Wide Web.
- Ferrandino et al. (1997)
- S.Ferrandino, A.Negro, V.Scarano, ``CHEOPS :
Adaptive Hypermedia on World Wide Web''. Proceedings of the
European Workshop on Interactive Distributed Multimedia Systems and
Telecommunicazion Services (IDMS '97), 10-12 Sept. 1997. Ed.
Springer-Verlag (Lecture Notes in Computer Science).
- Boutell
- T.Boutell, ``GD 1.2, A graphics Library for
fast GIF creation''. Quest Protein Database Center, Cold Spring
Harbor Labs (US).
- Hammond and Allison (1989)
- N. Hammond, L. Allison. `` Extending
Hypertext for learning: An investigation of access and guidance
tools''. In Sutcliffe,A. and Macaulay, L. (Eds.): People and
Computers, Cambridge University Press, 1989.
- Ibrahim (1994)
- B. Ibrahim, `` World-Wide Algorithm Animation''.
Computer networks and ISDN Systems, Vol. 27 No.2, Nov. 1994,
Special Issue of the First World Wide Web Conference, pp.255-265.
- Ibrahim and Franklin (1995)
- B. Ibrahim, S.D. Franklin. `` Advanced
Educational Uses of the World Wide Web''. Proc. of WWW95, 3rd
International Conference on World Wide Web.
- Nielsen (1990)
- J. Nielsen. `` Hypertext and
Hypermedia''. Academic Press Ltd, 1990.
- RDB
- ``RDB: Relational Database System''. http://www.rdb.com