Abstract: In this paper we describe our approach to develop adaptive hypermedia courseware and a prototype implementation. We applied the approach on a few topics of a university course on 'multimedia modeling and programming'. The fundamental structure of the domain is based on concepts, which are explained by documents. All information is stored in a database. Concepts are linked to documents and to other concepts through typed and weighted links. Each document has an associated level of difficulty. The student is guided towards appropriate documents based on information about his knowledge of each concept.
Keywords: Adaptiveness, navigation, educational hypermedia, link hiding
Hypermedia users with different goals and knowledge may be interested in different pieces of information and may use different links for navigation. Irrelevant information and links overload their working memories and screen [Brusilovsky 1996]. In order to overcome this problem, it is possible to use information represented in a user model and then adapt the content and/or the links to be presented to that user. Adaptive hypermedia systems build such a model with the goal of personalizing hypermedia.
Adaptation can be done either at content level (adaptive presentation), or at link level (adaptive navigation). In this paper, we focus on adaptive navigation support. More specifically, we want to reduce the cognitive overload in order to facilitate learning.
Before analyzing our approach we will start with some background information
on existing adaptive navigation techniques. In the section 3 we present
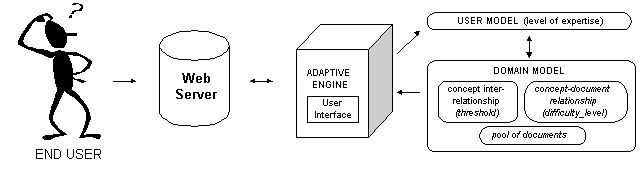
our system, called AHM, which consists of three main parts: the domain
model, the user model and the adaptive engine. Then, we discuss some implementation
issues and the drawbacks we have encountered. Section 4 is dedicated to
an informal evaluation of the system and the approach itself. Finally,
in section 5, we come to our conclusions and present the main open issues
in this research.
Our main goal with adaptation is to provide both local and global orientation support. This is currently done through the use of link hiding, but it will be reinforced by including adaptive annotation and concept maps in the model.
Link hiding is currently the most frequently used technique for adaptive navigation support. The idea is to restrict the navigation space by hiding links that do not lead to "relevant" pages, i.e. not related to the user's current goal or not ready to be seen. All kinds of links can be adapted according to this scheme by real hiding or by displaying hot words as normal text. Hiding can help to support both local and global orientation. Local orientation is achieved when, by limiting the number of navigation opportunities to reduce cognitive overload, it enables the users to focus on analyzing the most relevant links. On the other hand, by hiding links the size of the visible hyperspace is reduced and thus, global orientation is simplified. The courseware on Hypermedia Structures and Systems (2L670) from the Eindhoven University of Technology is a good example of link hiding. This course is totally on-line and uses a system developed there to track student progress and based on that, generate document and link structure adapted to each particular student. Links to nodes that are no longer relevant/necessary or links to information that the student is not yet ready to access are either physically removed or displayed as normal text [Calvi & DeBra 1997].
The main difference between their approach and our own, as far as adaptation is concerned, is that our links are typed and weighted and our nodes are also typed. In other words, as nodes we have concepts and documents; and as links we have relationships between nodes, which have associated weight (threshold for concept-concept relationships and difficulty-level for document-concept relationships. This will be explained in section 3.
Adaptive annotation is the augmentation of links with some form of comments, which can tell the user more about the current state of the nodes behind the annotated links. The annotations can be either textual or visual and can be used with all possible forms of links, like for instance, indexes or contextual links. Link annotation can be used to support local orientation by providing additional information about the nodes available from the current node. In order to provide global orientation support, annotation of links can function as a landmark, i.e., keep the same annotation for a node when the user looks at it from different positions in the hyperspace. Both hiding and annotation can help to provide local guidance, that is, to help the user to make one navigation step by suggesting the most relevant links to follow from the current node. Interbook illustrates the use of link annotation [Brusilovsky 1996a]. It is a tool for authoring and delivering adaptive electronic textbooks on the WWW. For each registered user, an Interbook server maintains an individual model of the user and applies it to provide adaptive guidance, navigation support and help.
Currently, annotation is not being used in AHM, but we plan to use it to replace the removal of links to nodes considered too easy.
There are other techniques to provide adaptive navigation support, such
as direct guidance, sorting, and map adaptation. We believe that these
techniques are not the most suitable ones for educational purposes because
they can lead to incorrect mental maps [Calvi 1997],
and so we are not going to elaborate on them.
The following subsections detail the AHM system components. The architecture of the system is summarized in Figure 1. The end user accesses the courseware through the web server, which launches the adaptive engine. The adaptive engine then accesses the database containing the user and domain models, selects the appropriate information for this user according to his/her user model and returns the information to the user via web server.
There are two possible types of nodes in our model: they represent either concepts or documents. Links are typed too and represent semantic relationships between nodes. Concepts can be related to other concepts (concept-concept relationship) or to documents (concept-document relationship). At present, we use only two link types for the concept-concept relationship: is_prereq_of and is_specialized_by, but there are other kinds of relationships which could be useful to enrich the model, such as is_related_to or contrasts_with. For document-concept links, there are also several possibilities that we have been considering, like for instance: explains, illustrates, tests, etc. However, for simplicity, only the type explains is being used currently.
The links in the model are also weighted. Associated to the is_prereq_of relationship between two concepts, there is a threshold, that represents the minimal expertise a student must attain on the prerequisite concept in order to access the more advanced concept. Each document has an associated level of difficulty with respect to the concept it explains, which varies from 0 to 99, and where a higher value means more difficult.
The documents are multimedia objects, such as text segments, figures or interactive demonstrations whose URL is stored in a database. A document may be related to more than one concept, since relationships are stored separately.
We explain our approach to adaptive hypermedia courseware by means of
an example courseware on 'multimedia modeling and programming', which in
fact contains only some topics from the actual course, hereafter called
the course.
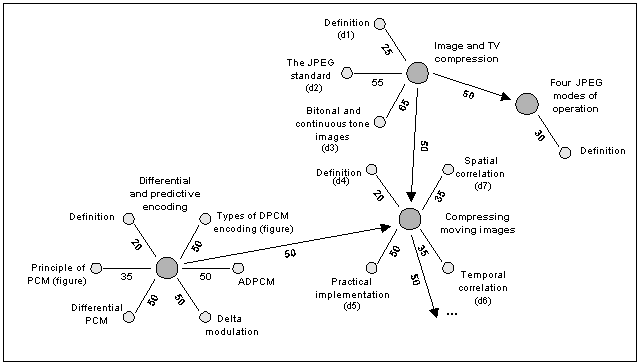
Figure 2 illustrates the course structure. Concepts are represented by large circles, and documents by small ones. A document explains the concept(s) it is linked to. The number associated to the link between a document and a concept indicates the level of difficulty of this document with respect to this concept. Edges linking two concepts represent the relationship is_prerequisite_of and the labels correspond to the level_of_expertise a student must have for crossing the link between two concepts. For example, in Figure 2, the concept Differential and Predictive Encoding (c1) is explained by 6 documents with levels of difficulty ranging from 20 to 50. This concept is a prerequisite for concept Compressing Moving Images (c2) with a threshold of 50, which means that, in order to access c2, the user must have accessed at least one of the documents with difficulty level 50, be it Differential PCM, Types of DPCM encoding or ADPCM.
It is also important to say that the adaptiveness in our approach affects only the so-called non-contextual links. Links embedded in text content are not reflected in the user level of expertise about the current concept.
The user model currently deals only with knowledge about each concept, which can vary from 0 to 99. We initialize student knowledge (or level of expertise ) for a particular user as 0 for every concept [see also Calvi 1997] (see example in Table 2 (c) at instant t0) and update this value after the student has visited a document related to the concept. When a student visits a document, his/her level of expertise is updated in the following way: when a document is visited, the difficulty level of the document updates the user expertise about the current concept if the former is superior to the latter. Tests are not being used yet, but they can be easily accommodated in the model as special documents, making it possible to evaluate previous or acquired knowledge.
The user model determines which documents are available to a student. Basic concepts, that have no prerequisites, can be accessed by a new student. Acquiring basic concepts enables the student to consult documents related to more advanced concepts. Associated to the is_prereq_of relationship between two concepts, there is a threshold, that represents the minimal level of expertise a student must have attained on the prerequisite concept in order to access the more advanced concept. By acquiring a concept we mean to get a level of expertise for it that is equal or superior to the associated threshold value.
The set of relevant concepts for a student at a particular moment includes basic concepts, as well as concepts whose prerequisites he/she masters sufficiently well, i.e. concepts whose prerequisites he/she has already acquired. The documents accessible to a particular student are called relevant documents. Relevant documents are those that explain a relevant concept. Additionally, among all documents referring to relevant concepts, the system chooses those having a difficulty level considered to be appropriate for that user at that particular instant. By appropriate we mean documents comprised in a calculated interval that excludes documents considered being too basic or too advanced. In practice, when appropriate documents are recalculated, the result is shown in the user interface. Links to 'too easy' documents are removed from the screen while links to more difficult documents - which have just become 'appropriate' - are added to it.
The user model is illustrated in Table 1. Each user is identified by
his/her user_id. Then each cell in the column associated to one
user represents a different concept already visited by this user and contains
the level of expertise, which represents the user's knowledge for
that concept.
| user-ids
concepts |
|
|
|
| Differential and Predictive Encoding |
|
|
|
| Image and TV Compression |
|
|
|
| Compressing Moving Images |
|
|
|
As an example of a basic concept, see concept Image and TV Compression in Table 2 (a). To see more clearly how a concept is acquired, let's look at Figure 2, the concept Image and TV Compression is a prerequisite for concept Compressing Moving Images with a threshold of 50 (directed arrow). Thus, in order to be able to access the latter, the user must first access, at least, the document The JPEG standard.
Things become more clear through the scenario shown in Table 2.
|
concepts
time |
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
concepts
time |
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
concepts
time |
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
||||||
|
|
|
||||||
|
|
|
||||||
|
|
|
||||||
|
|
|
||||||
|
|
|
||||||
Let's consider user u1 from Table 1, as well as concept Image and TV Compression with its documents Definition, The JPEG Standard, and Bitonal and continuous tone images (here respectively called d1, d2 and d3) and concept Compressing Moving Images with its documents Definition, Spatial correlation, Practical implementation and Temporal correlation (here respectively called d4, d5, d6 and d7) from Figure 2 and for the sake of space we use only document identifiers.
When the user u1 starts using the system (instant t0), her knowledge for all available concepts is 0 (Table 2 (c)). At instant t1, u1 chooses concept Image and TV Compression and visits the document d1 (Table 2 (b)), which is the only visible document for this concept at this moment (Table 2 (a)). d1 has a difficulty level of 30, thus, u1's level of expertise for concept Image and TV Compression becomes 30 (Table 2 (c)). u1's knowledge for other concepts remains unaltered. At t2, both documents d2 and d3 become accessible (Table 2 (a)), but u1 chooses to visit d3 first (Table 2 (b)). Her knowledge for Image and TV Compression is then updated to 60, which corresponds to d3's difficulty level (Table 2 (c)). We have shown here how the level of expertise of user u1 for concept Image and TV Compression in Table 1 was achieved. The procedure also holds for the other concepts.
Looking at Table 2 (a) at instant t5, we notice that document d4 which had been accessible till the instant before, has just become inaccessible. The reason is that the system now considers it too basic for this user. We may also notice that one or more documents became accessible at instants t4 and t5. A formal definition of the rules to generate both sets of relevant concepts and available documents as well as a rule to define the appropriate documents among the available ones can be found in [Pilar da Silva et al. 1997].
In Table 2 (c), the number shown below documents corresponds to their
level of difficulty. It is clear then that user level of expertise for
the concept Image and TV Compression at instant t2
reflects the difficulty level of the document she has just visited
(see Table 2 (b) instant t2).
ASP uses ActiveX Data Objects (ADO) as sources of data to retrieve information from a database. Rather than retrieving a large volume of data from a database, ADO first makes a connection to the database through a Connection Interface. The Connection Interface establishes the data source and its capabilities. This is done in a script by creating a connection object and setting that object to a particular data source. After the connection is established, a recordset object is created. A recordset object is a set of records (from a specified connection to a database) which is used to perform operations on only one record at a time. Finally, the recordset is based on a connection, and specify which records the recordset should contain. Once the information is retrieved, the script contained in an ASP page uses the ADO recordset to view, add, edit or delete data contained in the recordset's fields. Since connections and recordsets are separate objects, we can have multiple recordsets for each connection. The recordsets can be manipulated to be displayed as HTML or serve as parameters for a JAVA applet, for instance - as we do in our concept maps, which will be explained later in this section.

In the lower-left frame we display a list of accessible documents (the calculated set of relevant documents) for the current concept and the current user. The concept name has been recently added to the document frame. Clicking on a document on this list brings its content to the frame on the right. When a student accesses a document, his/her user model updated, and a series of consequences are triggered and reflected in the user interface, that is, new sets of relevant concepts and accessible documents are calculated and links to them are added to (or removed from) the screen.
Currently, in our model we have three concept maps. Two of the maps are static: the first one contains the basic concepts of the course with their documents. The second map contains all concepts of the course but no documents. The third map, however, is dynamically created while the user is using the course. It is called 'Where am I?' map and represents the current concept and its immediate neighborhood. This map contains the current concept with its documents, as well as the concepts which lead to current concept and the concepts to where the user can go from the current concept. At present, the maps are not 'clickable', i.e. they can't be used as a navigation tool yet.
Though our system is still a prototype, we decided to apply a preliminary experiment with the main goal of evaluating the system in general and re-direct the future of the work based on feelings of real users. Since the experiment and specially the content were not optimally prepared, we are not considering it as evaluation of the system and we cannot draw any conclusions from it. However, we have learned from the experience and based on that we have decided to incorporate some changes to the model. The lessons learned are listed as follows:
At present, the definition of concept structure, concept interrelationships
and associated thresholds, document-concept relationship and associated
difficulty levels are all defined manually.
As we were preparing our simple test of the system we realized that
difficulty level of documents is not sufficient to measure user
expertise about a concept and we shall include an additional attribute
to the relationship document-concept, called coverage for the time
being, that will state how important the document is for this concept or
rather, "how much" of the concept can be considered known if the document
is known. Both difficulty level and coverage will then be
taken into account together in order to define user expertise. Furthermore
we think that in order for the adaptiveness to be efficient, the user model
needs to be elaborated and other individual differences must also
be considered together with knowledge. Another important point in educational
hypermedia is that the content should be prepared very carefully,
for a badly prepared content can have a very negative impact on users'
feelings towards the system.
The main problem we have encountered so far is how to define relationships and deriving difficulty ratings and thresholds, since both tasks require very good knowledge of the content.
[Brusilovsky 1996] Brusilovsky, P., Methods and techniques of adaptive hypermedia. User Modeling and User-Adapted Interaction Journal Vol. 6, pp. 87-129, 1996.
[Brusilovsky 1996a] Brusilovsky, P., Schwarz, E. and Weber, G. A Tool for Developing Adaptive Electronic Textbooks on WWW . Proceedings of WebNet'96 - World Conference of the Web Society, October 16-19, 1996. San Francisco, CA, AACE. - pp. 64-69. http://www.contrib.andrew.cmu.edu/~plb/WebNet96.html
[Calvi 1997] Calvi, L. Navigation and Disorientation: A Case Study. Journal of Educational Multimedia and Hypermedia. V.6(3/4). pp. 305-320. 1997.
[Calvi & DeBra 1997] Calvi, L. & De Bra, P. Improving the Usability of Hypertext Courseware through Adaptive Linking . The Eighth ACM Conference on Hypertext - Hypertext'97. pp. 224-225. Southampton, UK. April 1997.
[De La Passardière & Dufresne 1992] De La Passardière, B. & Dufresne, A. Adaptive Navigational Tools for Educational Hypermedia. Computer Assisted Learning. pp. 555-567. Berlin, New York: Springer-Verlag. 1992. http://mistral.ere.umontreal.ca/~dufresne/Publications/ical91.htm
[Eklund & Zeilliger 1996] Eklund, J., Zeilliger, R. Navigating the Web: Possibilities and Practicalities for Adaptive Navigation Support. Second Australian World Wide Web Conference (AusWeb96). Southern Cross University. Lismore. Australia. 1996.
[Pilar da Silva et al. 1997] Pilar da Silva, D., Van Durm, R. Hendrikx, K. Duval, E. Olivié, H. A Simple Model for Adaptive Courseware Navigation. WebNet'97 World Conference. Toronto, Canada. November 1-5, 1997.
[Signore et al. 1997] Signore, O. et al. Tailoring Web Pages to Users' Needs . Proc. of the workshop "Adaptive Systems and User Modeling on the WWW" - 6th International. Conference on User Modeling. June 1997.
URLs:
Denise Pilar da Silva: http://www.cs.kuleuven.ac.be/~denisep/
Erik Duval: http://www.cs.kuleuven.ac.be/~erikd
Computer Science Department: http://www.cs.kuleuven.ac.be/cwis/dept-E.html
Katholieke Universiteit Leuven: http://www.kuleuven.ac.be/kuleuven/KUL_en.html