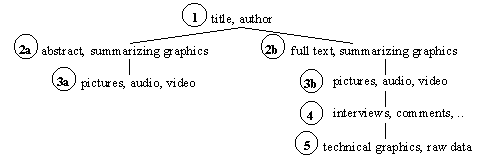
Figure 2 - Levels of detail in the presentation of news.
Abstract: This paper presents a framework for the generation of adaptive hypertexts for accessing on-line news servers. News servers contain huge amounts of information, concerning different subjects. The aim of our system is to present the most appropriate set of news (and advertisements) to each user, choosing the "right" detail level for each news item. This is obtained by using knowledge representation, user modeling and flexible hypermedia techniques.
Profile.
The profile of the users corresponding to
the stereotype is described by a set of slots (user features).
A probability is associated with each linguistic value of each feature:
this is the conditional probability that the user belongs to
the stereotype, given the linguistic value of the feature.
For example, in the stereotype "Professional financial reader",
the slot "age" specifies the probability
that the user is a professional financial reader, given
her/his age; e.g.:
p(Professional_Financial_Reader | age in [20,25]) = 0.1
The probability p(stereotype)
that a user belongs to
the class corresponding to each stereotype can be computed using
the initial data provided by her/him.
In particular, we assume that the features are
independent and thus p(stereotype)
is the product of the probabilities obtained from the slots
(by matching each slot with the user's data).
The independence assumption is reasonable for at least two
reasons: first, all the stereotypes in the same family contain
the same set of profile slots; second, we are interested
in the ranking of the stereotypes belonging to each family, rather than
in the actual values of their probabilities. For each family,
this ranking can be obtained
after normalizing the probabilities of the stereotypes in the family.
Prediction.
Slots that make predictions. The features in these slots are
different in the various stereotype families (and are not present in the
"Life styles" family). A probability is associated with each linguistic value
of each feature:
this is the conditional probability of
the linguistic value for the feature, given that the user
belongs to the stereotype.
The stereotype "Professional financial reader"
belongs to the "Interests" family and thus its predictions concern
the interest level in the various sections of the server.
Thus, in the example we have:
p(interest_in_economy = high | Professional_Financial_Reader) = 1
The probabilities predicted by a stereotype are computed as
follows:
p(featurei = valueij) =
p(featurei = valueij | stereotype) * p(stereotype)
where: p(featurei = valueij | stereotype)
is the value associated with valueij
of featurei
in the slot and p(stereotype)
is the probability that the user belongs to the
stereotype (the probability is computed using the "Profile" slots).
The stereotypes in different families produce non-overlapping predictions.
On the other hand, the stereotypes in each family are, in
general, not exclusive so that
there may be a partial match between a user and more than
one stereotype. In such a case the predictions have to be merged.
In order to do that, we assume that the contributions to the prediction
provided by different stereotypes are independent and we then
use an additive formula
to combine the contributions; e.g., if we have:
p(featurei = valueij) = X using a stereotype A
p(featurei = valueij) = Y using a stereotype B
then the combined prediction is
p(featurei = valueij) =X+(1-X)*Y.
Notice that again a normalization (concerning the different
values of each feature) provides the
final predictions.
The stereotypes make use only of the initial classificatory data
provided by the user. Thus their predictions may be coarse.
In particular, as regards the interests and expertise, the stereotypes
only make predictions on general subjects, i.e., on high level
sections and not on subsections. When no prediction on
a subsection is available, then this prediction
is initialized with the value associated with
its parent section.
All these predictions will be refined by the dynamic
user modeling rules (section 6).
Scoring rules
The first group of rules assigns a score to the (sub)sections
in order to decide whether they can be considered for
inclusion in the pages to be presented and, if they can,
at which detail level they should be presented.
These rules are applied for each (sub)section S and use
the information about the user's interest and expertise in the
topic of S (which is part of the user model).
Basically, the rules exploit probability matrices
that specify the probability of each detail level for
S, given the user's interest and expertise in
the topic of S. The probabilities have the following form:
p(level=i for section S | interest in S=X, expertise in S=Y) = Z
specifying that Z is the probability that the user wants to read
the news in S at
the detail level i if her/his interest in S is X
and her/his expertise in S is Y
(X and Y are linguistic values of
the features "interest" and "expertise").
For example,
p(level=4 for section S | interest in S = medium, expertise in S = medium) = 0.7
Notice that the matrices include a value 0 for the detail level:
this corresponds to the fact that no information has to be presented.
Since the user model contains the probability distribution for
the interest and expertise in each (sub)section S
(i.e., it contains the probabilities
p(interest in S=X), p(expertise in S=Y),
for all S and all linguistic values X and Y),
the application of the rules allows the computation of
a probability for each detail level of each (sub)section.
Selection rules
This second group of rules uses information about the user's receptivity
and the scores computed by the "scoring" rules
to make a final decision about the (sub)sections to be presented
and about the detail level for each (sub)section.
In particular, if the user has a low receptivity, the system may
reduce the number of (sub)sections and news and/or
the detail level of certain sections to shorten
the presentation.
Selection of the advertisements
The advertisements for each page
are selected using a third set of rules.
The selection depends
on the (sub)section/news displayed in the page
and on the classification
of the user according to the "Life Styles" stereotype family.
Indeed the target associated with each advertisement in
the database is specified in terms of classes in the "Life Style"
family.
The advertisements are selected by taking into account the
probability that the user belongs to each stereotype (class)
in this family.
Only the classes that are over a threshold are taken into account
and the selection is made considering advertisements for these
classes, with frequency proportional to the probabilities.
Notice that in this way the pages contain advertisements
for multiple targets and the fact that the user selects
a specific advertisement can be used for refining the user model
(as regards the "Life styles" classification).
if in section X the user selected links at level L in at least 60% of the cases
and in most of the other cases the user selected links at a level higher/lower than L'
then the user's interest for section X is M;
Each rule exploits an array M providing a probability
distribution for the linguistic values of the user's interest on
(sub)section X, i.e.:
M = (p(null), p(low), p(medium), p(high)).
For instance, the following is one of the rules associated with detail
level 4:
if in section X the user selected links at level 4 in at least 60% of the cases
and in most of the other cases the user selected links at a level higher than 3
then the user's interest for section X is: (p(null)=0; p(low)=0; p(medium)=0.7; p(high)=0.3)
If the user does not modify the structure of the news
proposed by the system,
no events are recorded and no rules are applied to update her/his model,
which we suppose to be a correct one.
We then have different sets of rules that make predictions
on the user's expertise, receptivity and life style.
As regards the latter, the system monitors the
advertisements (banners) visited by the user.
If s(he) often clicks on those corresponding to a given target
T, then a rule is activated making a prediction on the probability
that the user belongs to the class T.
Once a rule is fired, the user's features
occurring in the consequent of the rule are updated (the probability
distribution of the linguistic values is updated).
For each feature, the system evaluates the average between
the probability values in the user model and those
suggested by the rule.
Thus, the changes to the user model are smooth.
We made this choice because
the events monitored by the system are not certain; we prefer to
reduce the impact of new information with respect to the past history,
avoiding abrupt changes in the user model.
This is a choice and, in a sense, a conservative one;
other alternatives can (and will) be explored. Clearly,
if the description provided by the user model strongly differs
from the user's real features, our choice causes a slow updating
process.
The effect of revising the user model is that different (sub)sections,
news and advertisements may have
to be presented, or that a different detail level
has to be used for the news in some (sub)sections. Since changing
what is presented during a consultation may confuse
the user, the changes to the presentation are effective only to
the generation of the pages ((sub)sections and news)
that the user has not yet seen during the session.