Proceedings of the 2nd
Workshop on Adaptive Systems and User Modeling on the
WWW
When the Teacher learns:
a Model for Symmetric Adaptivity
Maria Barra Alberto Negro
Vittorio Scarano
Dipartimento di Informatica ed Applicazioni "R.M. Capocelli",
Università di Salerno
83025, Baronissi (Salerno), Italy
e-mail: {marbar | alberto
| vitsca}@dia.unisa.it
Abstract: In this paper, we present a model for
adaptive WWW hypermedia that is helpful in the authoring phase
phase since it efficiently provides a feedback to the author about the
behaviour of the system towards users.
The model is symmetric since it represents
users in terms of their "interest" toward information nodes in each topic and, viceversa,
it models information nodes in terms of the perceived "utility" toward users in each
category. In this way, adaptive behaviour can be presented toward the user but also to
the author, to help him/her in the design and tuning phases of the adaptive system.
We describe the motivations and the model, then we provide some examples and
details on simulations.
Keywords: user model, authoring system.
The World Wide Web (WWW) is evolved much during its short but stimulating
life. Developed as a system to share information within an organization,
it is, later, evolved into a global hypermedia network.
Among the many diverse ways of using the WWW, one of the most recognizable
is the educational usage of WWW: several educational systems based on WWW
[ Dwyer et al. (1995), Hammond
and Allison (1989), Ibrahim (1994), Ibrahim
and Franklin (1995)] were presented. It is well known that one of the characteristics
a WWW based educational system should have is adaptivity,
i.e. the ability to be aware of user's behavior so that it can take into
account the level of knowledge and, as a consequence, provide the user
with the right kind of documents.
Adaptive multimedia is a research area whose goal is to enhance the
functionality of hypermedia by building a model of the user and adapting
the response accordingly [ Brusilovsky (1996), Brusilovsky
(1997)]. Many systems have been presented for creating and deploying
adaptive multimedia application on the WWW. Among them, we cite AHA
[De Bra et al.(1998)] ISIS-Tutor
[Brusilowsky
et al. (1994)], InterBook [Brusilovsky
et al. (1996)], Cheops [Ferrandino et al.(1996)]
and many others (see the comprehensive survey by [Brusilovsky(1996)]).
It is useful for students and teachers alike, to think of an educational
system as a substitute of the real world experience. In this way, many
systems use paradigms well known to users as classrooms, lessons, homeworks,
lectures and so on (usually with the adjective virtual) and
it is now common to denote such applications as courseware.
The issue when authoring courseware is, usually, to provide interactivity
to students in a natural way so that it can become a fruitful help to the
learning process, rather than an obstacle. Of course, it means that
adaptive courseware must be even more carefully prepared. The problem,
here, is in experimenting and testing of the system. Usually, it is done
by asking students questions and comparing the interactions with the system
and paths followed in the hypertext [Eklund et
al.(1998)].
While this can be reasonable in small case tests, it can be seen that
in applications of a certain size and that run for a non negligible amount
of time, analysis of the huge amount of data can be a real problem.
Still, for large case applications, it becomes much more important to be
able to get quick feedback from the system by synthetic information.
In this paper we present a model for adaptive systems on the World
Wide Web that is meant as an authoring aid as well as a knowledge
model. The model is meant to provide a unifying view to the
design-experiment-evaluate authoring scheme (shown to the right)
as a continuos loop
where the evaluation process provides help and feedback to the
system designer and author. Our model has several
characteristics. We outline them here and refer the reader to the
conclusions where further comments to these aspects are presented:
The model is meant to provide a unifying view to the
design-experiment-evaluate authoring scheme (shown to the right)
as a continuos loop
where the evaluation process provides help and feedback to the
system designer and author. Our model has several
characteristics. We outline them here and refer the reader to the
conclusions where further comments to these aspects are presented:
-
The model is symmetric: while applied toward users to provide adaptivity,
it is also applied to information nodes in order to
measure interests by categories of users.
-
The model is efficient: it allows easily recognizable patterns for a quick
analysis (even automatizable) of system performances.
-
The model is natural: it is a common experience for educators to learn
from the students, in the same moment the lesson is taking place. Adaptive
systems have always provided a personalized response to students but it
is as much important to provide responses to the teacher as well.
-
The model is tunable: it allows tuning parameters since courseware is deployed
in a variety of situations and time spans. The responses (feedback) of
the model can be given at different intervals, therefore allowing for flexible
interactions.
-
The model is general: it can be changed to work for different knowledge
models.
Before we go into further details about the model, we want to explain
how the model can be used to build an adaptive hypertext system. In our scenario, three (type of) characters
are playing: the user(s), the author of the adaptive system and
information node(s) (i.e. pages).
Two are the main goals that our model wants to fullfil: the first one
is to adapt responses to user's interests while the the second is to
provide (at the same time) useful feedback to the author so that he
can detect inconsistencies in the system and can possibly act
accordingly. Such inconsistencies can be (for example) information
nodes that were supposed not to be useful/interesting to a certain
type of user (during the design of the knowledge base) and that (on
the field) revealed themselves as particolarly requested.
Our model provides this dual (symmetric) adaptivity by synthetically
classifing both the users and the information nodes: the symmetry
allows to adapt responses to users' behaviour and
"adapt" the nodes to the signs of possible
misrepresentation that are perceived by the system.
During interactions, in fact, users and information
profiles are manipulated and processed. Users' profiles are
changed to provide adaptable contents at run-time while information
nodes' profiles are manipulated to provide synthetic, efficient feedback to
the author. No explicit interaction with the system is requested by
the model: we assume that just the act of "choosing and following a
link" is a sign of interest (establishing a relationship) between the
user (with his/her current profile) and the information node (with the
profile assigned by the author).
We describe how to use the model to provide useful
feedback to the author. The idea is that the author is responsible for
assigning (initial) profiles to information nodes, according to domain knowledge,
design rules
and past experiences. After a certain period of time, the author needs
to check the system to detect possible errors by examining the
information nodes' profiles. In this context, we feel that quick signs that something is
not expected can be useful given the size of hypertext and the large number of
interactions.
Our model is able to collect and process the behaviour of users toward
each single information node and is able to present a dynamic profile
of the node that can be interpreted by the author to suggest changes in the
profile of the node. Dynamic profiles can also be used by the system to trigger
"alarms" to warn the author of unexpected behaviour.
In this paper we deal mainly with the issue of feedback to the author: mechanisms to
adapt the presentation and the navigation based on users'
profiles can be easily mutuated by the ones
in [Barra et al. - 1
(1998)], [Barra et al. - 2 (1998)]
and [Calabrese et al. (1998)] where, for example, mechanisms to
present personalized "Top 10 choices" are shown.
Here we briefly present the
model. In the model there are students and information
nodes. Of course the model is not restricted to the educational
setting but the description flows naturally when one refers to
students.
The main characteristic of the model is symmetry: each
time an interaction between a studen and an information node occurs,
we derive some concise information about the student (for the
adaptivity) and for the information node (as a feedback for the
author). A similar model has proven itself useful in Electronic
Commerce scenarios (see [Barra et al. - 1
(1998)], [Barra et al. - 2 (1998)]
, [Calabrese et al. (1998)]).
We now formally define the profiles and the model. Let A(x,y) be a
subset of the set obtained by the product of {1,...,x} by
[0,1]^y i.e. an item a belonging to A(x,y) is a pair
(c, <a1,a2,...ay>) where the first item is called a
category and the vector of y items is called
configuration. A legal configuration has all its
elements summing up to 1. In A(x,y) there is an implicit
partition in subsets consisting of all the items a that have
the same category.
Now, a symmetric adaptive system is
composed by two sets:
-
a set of students S=A(K, T) where students are partitioned among
the K categories in S1, S2, ...,
SK.
-
a set of information nodes N=A(T,K) where nodes are partitiones among the
T topics in N1, N2, ...,
NT.
A student A in S is, therefore, characterized by his/her category
and the configuration vector has as many components as the number of
topics T available. In other words, in our model students are
roughly partitioned in subsets, but each one has his/her specific and
particular configuration vector showing how he/she likes the topics
which the information nodes are partitioned into. At the same
time a node B in N belongs to a specific topic and its
configuration vector has as many components as the number of categories
K among the students. That means that we can subdivide
information nodes in topics but each node has a configuration vector
indicating how it is liked/accessed by students within the same
category. In this model we can see, among others, two useful
characteristics: one can easily statically define categories of
students and information nodes while the configuration of each item
(both students and nodes) can be dinamically modified (more
details follow later) as relationships are established at run-time
between one student and one node. Moreover, while grouping students/information nodes
by category/topic is general and rough, each configuration vector refers to
a specific student/information node, thus providing a detailed view of its
characteristics.
Now, when student A with profile
Prof(A)=(c , <s1,s2,..,sT>) accesses an information node B with profile
Prof(B)=(d, <n1,n2,..,nK>) the model evaluates a
measure of the surprise of this by evaluating
Surpr(A,B) = 1 - sd nc
The value Surpr measures the
information that is given to the system when the student is
reading/accessing/interacting with that page and goes from 0
(absolutely expected) to 1 (maximum suprise).
Now, what happens when a student A is related to a node
B? The main idea is the following: we want to update
student configuration and node configuration, as well, according to
the suprise that is generated. Informally, if there is not surprise,
we do not want to modify the configurations since the system appears
to be describing the student and the node pretty much well. If there
is surprise, we would like to update the student configuration,
showing an unusual (given the previous configuration) interest in a
certain node and, at the same time, we would like to show to the
author that something unusual happened to that information node, since
it appears to be interesting to students that were not
really supposed to be attracted.
The process, here, lacks the symmetry elsewhere present in the model.
We do want to update student profiles as soon as possible since the following
interactions should be directed by changes in student's behaviour. On the
other hand, we would not like the configuration of our information node
be istantaneously changed each time a student generates a surprise. In
fact, nodes are accessed by many students at once and, if nodes configurations'
are changed each time one student accesses the node, then other
students could not be able to retrieve the page that they previously accessed
by using adaptivity techniques (like links sorting, for examples) base
on nodes configurations. This would easily create confusion in the learning
process. Still, we want to keep track of unusual accesses since they can
be useful for the author during the authoring loop process described before.
Therefore, let us describe the update operation for the student's profile,
first, and, then, show how to update the information node's profile.
Assume that student A with profile Prof(A)=
(c , <s1,s2,..,sT>) accessed
information node B with profile Prof(B)=
(d, <n1,n2,..,nK>) with surprise
Surpr(A,B). Now, the configuration of student is changed only
if Surpr(A,B) is greater than sd . In this case, we change the value
sd with the
suprise Surpr(A,B) and, then, normalize the vector so
that the configuration is
legal i.e. it sums up to 1. This happens each time a student accesses
a node that generates surprise. The effect of surprises is time
sensitive since other surprises take place and the normalization
process in the vector brings "old" surprises (not reinforced by
successive surprise on nodes of the same topic) to fade out.
What happens to information node B? If a surprise takes place
we might specularly act in the same way as students' profiles. This has proven
iselfg a successful technique for quickly reacting to users' indications, as it
is done in the model presented and tested for Electronic Commerce in
[Barra et al. - 1 (1998)], [Barra
et al. - 2 (1998)], [Calabrese et al. (1998)].
We add to information node profiles an additional configuration vector M
that will hold the surprises (when high) of interactions by users.
Given an information node
B, its profile is now, Prof(B) =
(d, <n1,n2,..,nK>, <m1,m2,..,mK>).
The additional configuration vector <m1,m2,..,mK> is called the dynamic
configuration as opposed to <n1,n2,..,nK> that is the static configuration,
i.e., the configuration as chosen by the author.
In this way, the author can regularly check for wrong settings of information
nodes while keeping the system stable and coherent with students
expectations over a short time span.
Then, given, again, that student A with profile Prof(A)=
= (c , <s1,s2,..,st>)
accessed the information node B with profile Prof(B) =
(d, <n1,n2,..,nK>, <m1,m2,..,mK>)
with surprise Surpr(A,B) we update the dynamic configuration
vector of B
depending whether Surpr(A,B) is greater than mc
as follows: the value mc is changed to
Surpr(A,B) in the dynamic configuration vector and, then,
it is made legal by normalizing the sum of values to 1.
Notice that we do not change the static configuration vector and mechanisms to provide
adaptive presentation or navigation to students do rely on static configuration vectors.
When the author wants to check the behaviour of the system he/she can check the distance
between the static and the configuration vector and use it as an efficient sign of
unexpected behaviour. Of course, automatic mechanisms of warning can be easily
implemented by triggering an alarm if, e.g., dynamic configurations of more than
30% of the information
nodes are "far" from the original, assigned, static configuration.
In our model, knowledge domain must be
organized and subdivided in categories. Categories can (for example) represent
different users' interest.
Information proposed in courseware, during authoring phase, are also related
to types of students, and each information node is examined to help configuration of its
initial profile that shows how the node is appealing/useful to each student category.
In the same way, students' configurations show relationships with categories of
information nodes. Of course, we assign a sterotypical configuration to each student depending
which category the student belongs to, and, later,
(depending on his/her choices) the configuration will evolve in a personal sign of
interests/attitude toward each topic of information nodes.
Our example is about a courseware on Java language for undergraduate
students in Computer Science Major at the University of Salerno.
| Students Initial Stereotypes
|
Category
(Specialization) |
Configuration |
|---|
| java.net | java.lang | JDBC | java.awt | |
| Networking | 0.5 | 0.2 |
0.05 | 0.25 |
| Models | 0.1 | 0.4
| 0.3 | 0.2 |
Information
Systems | 0.6 | 0.2
| 0.1 | 0.1 |
Our School offers three different specializations based on Networking,
Models and Information Systems and each student belongs to one of them.
Of course, we use these 3 specialization degrees as students' categories and we use
domain-specific knowledge to
infer, for example, that a
Networking student is interested more in communication packages offered by Java
than in other packages.
Of course, some interest will be shown toward general topics
such as the Java language package, and toward moderately related topics, like,
for example, applets and Graphical User Interface for designing distributed
applications over the World Wide Web.
In this way we can come up with students stereotypes shown above.
| Base Configuration for Information Nodes
|
| Topics |
Configuration |
|---|
| Netw. | Models | Inf. Sys. |
| java.net | 0.6 | 0.2 | 0.2 |
| java.lang | 0.2 | 0.2 | 0.6 |
| JDBC | 0.2 | 0.6 | 0.2 |
| java.awt | 0.1 | 0.4 | 0.5 |
Now, let us show categories for the knowledge domain.A rough partition could divide
our Java courseware into four topics:
the java.net package and RMI middleware, the java.lang and
java.io
packages, Java DataBase Connectivity support, and java.awt and
java.applet. Then, the author must come up with a configuration for
each information node. It can be easier to have a base configuration for each topic
(such as the one presented on the left) to begin with and change it, on a case-by-case analysis,
for each node. At the beginning, the configuration is assigned both to static
configuration and dynamic one.
We now show few sample
interactions between a user and an information node and observe the changes in
the configurations, both student's and the dynamic configuration of the node.
Being focussed on the authoring issue we concentrate on nodes' profiles but
we briefly mention also students' profiles. We show a sample of students'
configurations in the following table. We also show a table of some Java classes
as information nodes assuming that their configurations are just set by the author so that, for
each node, the dynamic configuration is the same as the static one.
We, now, let some students interact with some pages and observe changes to
node's profiles.
| Student | Specialization |
Configuration | Peculiar Interests |
|---|
| java.net | java.lang | JDBC | java.awt | |
| V | Networking
| 0.4 | 0.2 | 0.1 | 0.3
| Client-server Applications through WWW |
| M | Models
| 0.1 | 0.4 | 0.3 | 0.2
| Experiments and simulations with large data sets |
| P | Networking
| 0.6 | 0.2 | 0.1 | 0.1
| Distributed applications not strictly related to WWW |
| G | Inf. Sys.
| 0.3 | 0.1 | 0.4 | 0.2
| Remote interfaces to DBMS |
| F | Models
| 0.1 | 0.5 | 0.1 | 0.3
| Algorithms with user-friendly graphic interface |
| Nodes | Topics |
Initial Dynamic and
Static Configuration |
|---|
| Netw. | Models | Inf.Sys. | |
|---|
| Socket class | java.net
| 0.5 | 0.2 | 0.3 |
| Remote interface | java.net
| 0.8 | 0.1 | 0.1 |
| Frame class | java.awt
| 0.2 | 0.4 | 0.4 |
| System class | java.lang
| 0.3 | 0.5 | 0.2 |
| Driver jdbc | java.jdbc
| 0.4 | 0.1 | 0.5 |
| File class | java.lang
| 0.3 | 0.3 | 0.4 |
1.
Let student P choose Frame class as next page.
His profile is
Prof(P)= (Networking, <0.6,0.2,0.1,0.1>) while node's profile is
Prof(Frame class) = (java.awt, <0.2,0.4,0.4>, <0.2,0.4,0.4>).
The system can evaluate the product between the interest
in P's profile toward java.awt topic and page "relevance" to
students in Networking specialization , that is, p=0.1*0.2=0.02.
Then surprise Surpr(P, Frame class)=1-p=1-0.02=0.98 is evaluated.
Now, surprise is compared to P's
interest in java.awt topic and, since larger, surprise is inserted in that place.
Then, surprise is compared to the value in the dynamic configuration of node
Frame class and similarly inserted.
P's profile is normalized to
Prof(P)= (Networking, <0.32,0.11,0.05,0.52>)
while the profile of Frame class is
Prof(Frame class) = (java.awt, <0.2,0.4,0.4>, <0.56,0.22,0.22>).
2. Now, student P chooses to read information about Remote interface, next, whose profile is
Prof(Remote interface) =
(java.awt, <0.8,0.1,0.1>, <0.8,0.1,0.1>).
Since the product between relative interests is p=0.32*0.8=0.256 and the surprise is
Surpr(P, Remote interface)=1-p=0.744,
only P's profile is changed (and normalized) while node's profile is not changed.
Notice also that, if student P had interacted with node Remote Interface before
his interaction 1 with Frame class, there would be not surprise in both profiles.
3.
If student F with profile Prof(F)=(Models, <0.1,0.5,0.1,0.3>)
interacts with Frame class node whose profile is Prof(Frame class)=
(java.awt, <0.2, 0.4, 0.4>, < 0.56, 0.22, 0.22 >) the system evaluates the
product p=0.3*0.4=0.12 and Surpr(F, Frame Class)=1-0.12=0.88.
Since surprise exceeds the values in both F's and Frame Class's configuration
we change both profiles and node's profile becomes Prof(Frame class)=
(java.awt, <0.2, 0.4, 0.4>, < 0.34, 0.53, 0.13>).
4.
We want see, now, changes in profile of Frame class
if student G reads the page.
Student's profile is Prof(G)= (Information Systems,
<0.3,0.1,0.4,0.2>) while, now, information node's profile is
Prof(Frame class)=
(java.awt, <0.2, 0.4, 0.4>, < 0.34, 0.53, 0.13>). The modification to
node's profiles is performed and the obtained profile is
Prof(Frame class)=
(java.awt, <0.2, 0.4, 0.4>, < 0.18, 0.29, 0.53>).
Few comments on this brief example: it is clear that, if many accesses to page
Frame Class are done by students with profiles similar to student
G's, for example, then the dynamic configuration will show a precise sign
that the page is interesting to students of category Information Systems.
On the contrary, many accesses by students with profiles similar to P's or
(respectively) to F's, will change dynamic configuration accordingly, signalling
unexpected interest from other categories. Notice also, that access 2 by user P
to node Remote Interface generated a certain amount of surprise since, P's
configuration brought some memory of his access (#1) to "unexpected" classes.
This example is meant to give an idea of how profiles evolve over few interactions.
Of course, this situation is not where the model is useful: it is mainly intended, in fact,
for situations where many accesses are done and one wants a quick feedback over
information nodes profiles. In the next section some results of simulations are given
to further validate our model.
Simulations are particularly tricky in a dynamic system where there
is a feedback that brings output of the system (updated configurations)
as input to the system itself moments later. This is the case, in our model,
of students' and nodes' profiles that are changed and reused moments later at the next
interaction.
We borrowed some ideas from
the theory of sequential switching network analysis (see
[Preparata(1985)]). In order to validate the
design of such networks, the analysis
is done by "cutting" wires that provide feedback and analyize the system
as a common combinatorial circuit. If the values at the two endpoints of
the "cut" appear to be the same, then it means that the circuit reaches
(after a certain time) a stable and predictable behaviour.
Our simulations are working along the same guidelines: we
assume that user profiles are correct and see if a different
percentage of
"expected" and "unexpected" students interact with a given page, one can
infer the initial conditions (with a reasonably high probability) by the
value provided by the dynamic configuration vector that holds the surprises
of the interactions. Once the feedback to author is proven helpful, the
simulations will be done the other way around and test interactions of
one user with many information nodes.
Simulations reported here only cover half of this methodology, being focussed on
the feedback to author issue. A full paper (in preparation) will report on full
simulations, i.e. including users' profiles.
Our simulations involve three categories of students C1, C2, C3
and four topics of information nodes T1, T2, T3, T4. Students' profiles are
generated by slightly perturbing (and normalizing) standard profiles at random.
Then, the number of interactions of students of any category is fixed and interactions
are made in random order. This generates a dynamic configuration vector.
The experiment is repeated (with different random
users) and then the results are evaluated.
| User Stereotypes for generating users |
|---|
| Stereotype | Configuration |
|---|
| T1 | T2 | T3 | T4 | |
| U1
| 0.6 | 0.1 | 0.2 | 0.1 |
| U2
| 0.3 | 0.5 | 0.1 | 0.1 |
| U3
| 0.2 | 0.1 | 0.6 | 0.1 |
| Information nodes |
|---|
| Node | Topic |
Configuration |
|---|
| C1 | C2 | C3 |
| I1 | T1
| 0.7 | 0.2 | 0.1 |
| I2 | T2
| 0.3 | 0.5 | 0.2 |
| I3 | T3
| 0.2 | 0.2 | 0.6 |
| I4 | T4
| 0.3 | 0.4 | 0.3 |
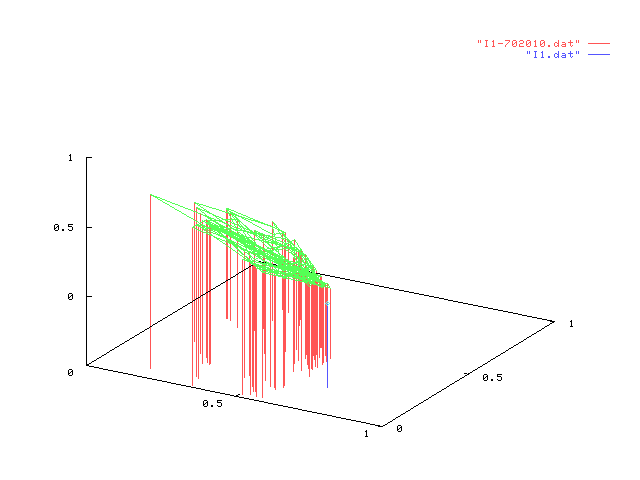
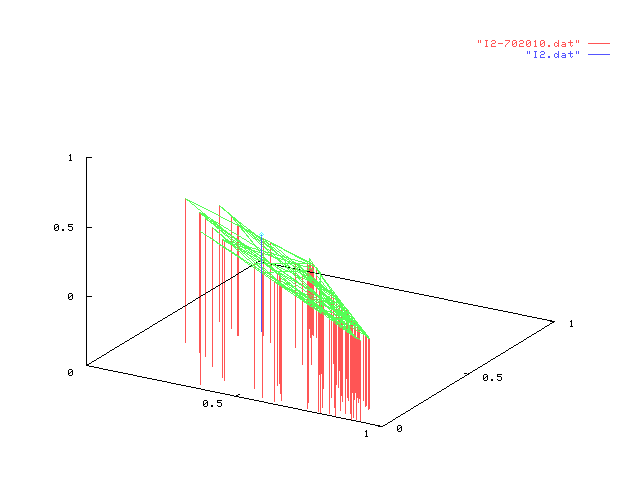
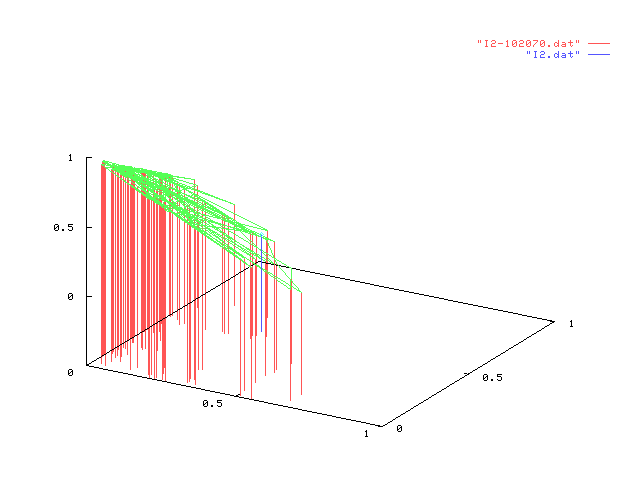
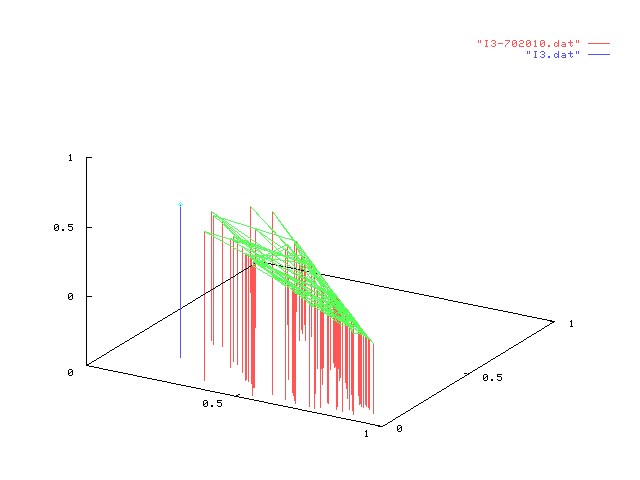
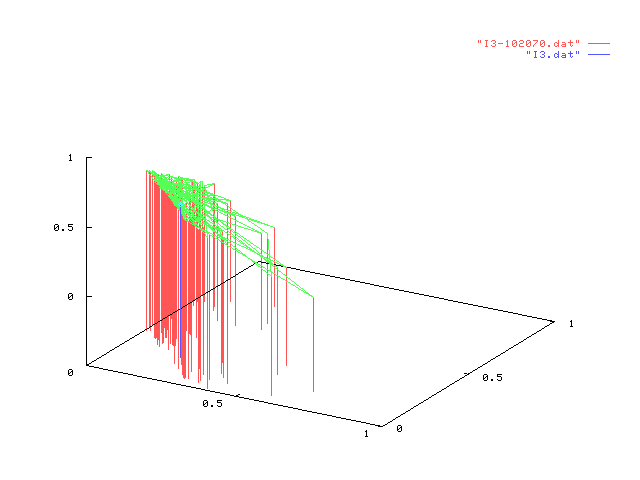
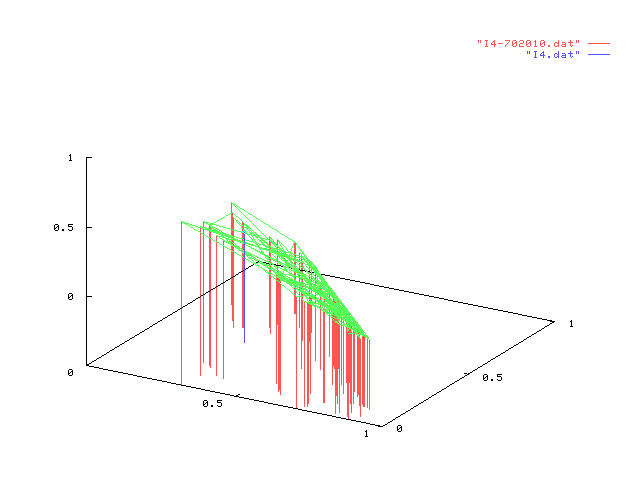
In each figure in the table below, we represent the result of one experiment on
a given information node. Each experiment consists of 100 points each one representing
the value of dynamic configuration vector after 1000 different users interacting in
random order. Static configuration is shown in blue.
To generate users we begin with a table of three stereotypes (shown left).
Users are generated randomly in two steps. First a percentage of
users' types is chosen: in simulation figures, percentages are 70%,
20%, 10% for each of the three users stereotypes (first column) and 10%, 20%, 70%
(second column).
| Node | Simulation results
|
| U1=70%, U2=20%, U3=10% |
U1=10%, U2=20%, U3=70% |
| I1 |
 |
 |
| I2 |
 |
 |
| I3 |
 |
 |
| I4 |
 |
 |
Secondly, for each stereotype and in proportion to the assigned percentage,
a number of users' profiles are generated by slightly altering
(randomly) one position of the profile and normalizing the
result.
In this way, we assume that users of a given stereotype different and, yet, similar enough
to represent the "typical" interaction with nodes.
Simulation figures shown above can, first, validate our model since points (in each
drawing) tend to cluster together, therefore showing the same behaviour over
different interaction sets with similar characteristics. Then, by comparing the dynamic
configuration with the static one (shown in blue) one can have an idea of the "movement"
taken by the configuration vector over several thousand of interactions, suggesting
or supporting choices to change the static configuration of a node.
We can also briefly comment some of the experiments above: the leftmost in the first row
shows that almost all points have the
same behaviour in each trial but, also,
the static configuration is not much far
from the any other dynamic configuration.
This result is expected since percentage of stereotypes in random users somewhat followed
the static configuration vector of I1. The opposite can be seen to happen,
for example, for interactions between I4 in the second column
(percentages 10%, 20% and 70%) due to an unexpected high rate of access by user in category
C3.
It is now the time to further elaborate on the characteristics of the model
as mentioned in the introduction.
Symmetry of the model provides a simple way to get results of
any kind from the system. For example, one can think of applying our model
to apply well-known techniques like links sorting but also to help system
manager to identify students that should have read some nodes and did not,
providing a kind of monitoring over the learning process.
Efficiency of the model is crucial over any distributed setting:
no need to manually analyze tons and tons of logfiles of users' interactions,
just a quick view to the configuration can provide useful information to
the author that can, later, use the logfiles to elaborate some response
to unexpected situations.
The model puts itself in a natural perspective for a teacher:
as we said before, it is a common experience to "tune up or down" a lesson
depending on the feedback of students. This is an aspect that greatly helps
the usability of adaptive systems. In fact, these systems are, actually,
often used by the same people who designed them: of course they have a
consistent, complete view of the system and can "feel" if something goes
wrong. A system that automatically provides information on tuning is an
important step, in our opinion, toward a wider acceptance and usability
of adaptive multimedia systems.
The model also allows several tuning parameters: for example
one can choose to provide feedback at different time intervals and to automatically
detect "serious" inconsistencies and notify to the author asynchronously.
Finally, the model is general: several other knowledge models
use (in our terms) configuration vectors and our feedback model can be
easily added to their model so that authoring can be made easier in a variety
of models and situations.
The model is, actually, under study in a computer-simulated environment.
Next planned step is to apply the model in a hypermedia that is actually
under design to help orientation of high school students in colleges. The
goal is to provide a game-like environment and have a profile of the student
that can be used for choosing the right school. The project is now entering
the design phase and is planned to start with a quick, working prototype
that will allow a real-case test before the final deployment of the
package.
-
Barra et al. - 1 (1998)
-
M.Barra, G.Cattaneo, M.Izzo, A.Negro, V.Scarano ``Symmetric Adaptive
Customer Modeling for Electronic Commerce in a Distributed Environment
'', Proc. of International IFIP Working Conference on ``Trends in Distributed
Systems for Electronic Commerce'', Lecture Notes in Computer Science,Springer-Verlag
Eds. June 3-5, 1998.
-
Barra et al. - 2 (1998)
-
M.Barra, G.Cattaneo, M.Izzo, A.Negro, V.Scarano ``Symmetric Adaptive
Customer Modeling for Electronic Commerce in a Distributed Environment
'', Proc. of International IFIP Working Conference on ``Trends in Distributed
Systems for Electronic Commerce'', Lecture Notes in Computer Science,Springer-Verlag
Eds. June 3-5, 1998.
-
Brusilovsky et al.(1994)
-
P. Brusilovsky and L.Pesin. ``ISIS-Tutor: an adaptive hypertext learning
environment''. Proc. of JCKBSE '94, Japanese-CIS Symp. on knowledge-based
software engineering. Pereslavl-Zalesski, Russia. 1994.
-
Brusilovsky (1996)
-
P. Brusilovsky. ``Methods and techniques of adaptive hypermedia''.
User Modeling and User-Adapted Interaction, 6 (2-3), pp. 87-129, 1996.
-
Brusilovsky et al. (1996)
-
P. Brusilovsky, E.Schwarz, G.Weber. ``A tool for developing adaptive
electronic textbooks on WWW''. In Proc. of WebNet96, San Francisco, CA,
USA. 1996.
-
Brusilovsky (1997)
-
P. Brusilovsky. ``Efficient techniques for adaptive hypermedia''.
In: C. Nicholas and J. Mayfield (eds.): Intelligent hypertext: Advanced
techniques for the World Wide Web. Lecture Notes in Computer Science, Vol.
1326, Berlin: Springer-Verlag, pp. 12-30, 1997.
-
Calabrese et al. (1998)
-
G.Calabrese, R.Capobianco, M.Izzo, V.Scarano ``Un Agente intelligente
e dinamico a supporto delle transazioni di acquisto ''. Convegno Annuale
AICA 98. Napoli, 18-20 Novembre 1998.
-
Dwyer et al. (1995)
-
D. Dwyer, K. Barbieri, H.M. Doerr. `` Creating a Virtual Classroom
for Interactive Education on the Web''. Proc. of WWW 95, Third Int.
Conf. on World Wide Web.
-
De Bra et al. (1998)
-
P. De Bra, L. Calvi `` AHA: A Generic Adaptive Hypermedia System''.
Proc. of the 2nd Workshop on Adaptive Hypertext and Hypermedia at the 9th
ACM Conference on Hypertext and Hypermedia (Hypertext 98), Pittsburgh,
USA.
-
Eklund et al. (1998)
-
J. Eklund, P.Brusilovsky `` The value of Adaptivity in Hypermedia
Learning Environments: A Short Review of Empirical Evidence''. Proc.
of the 2nd Workshop on Adaptive Hypertext and Hypermedia at the 9th ACM
Conference on Hypertext and Hypermedia (Hypertext 98), Pittsburgh, USA.
-
Ferrandino et al. (1997)
-
S.Ferrandino, A.Negro, V.Scarano, ``CHEOPS : Adaptive Hypermedia
on World Wide Web''. Proceedings of the European Workshop on Interactive
Distributed Multimedia Systems and Telecommunicazion Services (IDMS '97),
10-12 Sept. 1997. Ed. Springer-Verlag (Lecture Notes in Computer Science).
-
Hammond and Allison (1989)
-
N. Hammond, L. Allison. `` Extending Hypertext for learning: An
investigation of access and guidance tools''. In Sutcliffe,A. and Macaulay,
L. (Eds.): People and Computers, Cambridge University Press, 1989.
-
Ibrahim (1994)
-
B. Ibrahim, `` World-Wide Algorithm Animation''. Computer
networks and ISDN Systems, Vol. 27 No.2, Nov. 1994, Special Issue of
the First World Wide Web Conference, pp.255-265.
-
Ibrahim and Franklin (1995)
-
B. Ibrahim, S.D. Franklin. `` Advanced Educational Uses of the
World Wide Web''. Proc. of WWW95, 3rd International Conference on World
Wide Web.
-
Nielsen (1990)
-
J. Nielsen. `` Hypertext and Hypermedia''. Academic Press
Ltd, 1990.
-
Preparata (1985)
-
F.P. Preparata. `` Introduction to Computer Engineering''.
Harper & Row, New York (USA), 1985.