A Case-Based Approach to Adaptive Information Filtering for the WWW
Mauro Marinilli, Alessandro Micarelli and Filippo Sciarrone
Dipartimento di Informatica e Automazione Università di Roma Tre
Via della Vasca Navale, 79 I-00146 Roma, Italia
email: marinil@dia.uniroma3.it
- telephone: +039-06-55173205
Abstract: In this paper we present a case-based approach we have used for the realization
of an Information Filtering system for the Web. The system is capable of
selecting HTML/text documents, collected from the Web, according to the
interests and characteristics of the user. A distinguished feature of the
system is its hybrid architecture, where a sub-symbolic module is integrated
into a case-based reasoner. The system is based on a user modeling component,
designed for building and maintaining long term models of individual Internet
users. Presently the system acts as an intelligent interface for the Web
search engines. The experimental results we have obtained are encouraging
and support the choice of the case-based approach to adaptive Information
Filtering
Keywords: Information Filtering, User Modeling, CBR,
Artificial Intelligence, Knowledge Representation
1. Introduction
The Internet has rapidly become the main route for information exchange
world-wide. Besides the problem of bandwith, the growth of Internet and
the World Wide Web makes it necessary for the end user to cope with the
huge amount of information available on the net. Filtering information
[Belkin:92] is a problem becoming increasingly
relevant in information society. The issue of information filtering involves
various kinds of problems, such as (i) designing efficient and effective
criteria for filtering, and (ii) designing a friendly, non-obtrusive, intelligent
interface to lead the user to the most interesting information, according
to her/his interests. In this work we present an Information Filtering
system, we have developed for selecting HTML/Text documents from the World
Wide Web. The system selects the documents according to the interests (and
non-interests) of the user, as desumed by the system through the interaction.
To do so, the system makes use of a User Modeling ad-hoc subsystem, particularly
conceived for Internet users. One distinguishing feature of the presented
system is its hybrid architecture: a combination of a Case-Based Reasoner
with a sub-symbolic module (here, an artificial neural network). The system
has been developed in Java on a PentiumII®-based platform. The
evaluation of the system is based on an empirical approach and makes use
of a non-parametric statistics for testing hypotheses on the system behavior.
The paper is structured as follows. In Section 2 the general architecture
of the system is presented. In Section 3 we present briefly the user modeling
component. In Section 4 we describe the anatomy of the Information Filtering
component. Then we describe the results of the evaluation of the integrated
system. In a concluding section we give some final remarks.
2. The General Architecture
The general architecture of the system is shown in Figure 1.
It is composed of the following modules:
-
The User Model, representing the characteristics and the information
needs of a particular user;
-
The User Modeling component, capable of dynamically building the
user model, as desumed by the system through the interaction;
-
The External Retriever, which interfaces with AltaVista;
-
The Information Filtering component, which selects the relevant
documents for the user, according to the content of the User Model;
-
The User Interface, which manages the interaction.
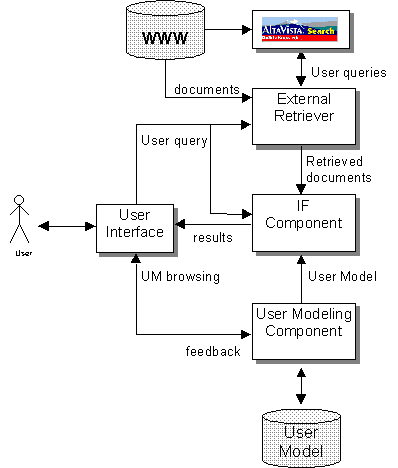
Figure 1. The General Architecture of the System.
When a user interacts with the system for the first time, her/his user
model needs to be made from scratch. In order to quickly build a reliable
model an interview is proposed to the user, expressing an interest score
[1] for each of the domain categories, as show in
figure 2. The user sets a query to the system that
in turn posts it to the external WWW search engine, obtaining documents
that are filtered and returned to the user. In the filtering process the
systems works using two different levels of refinement, a first, coarse
one, and a more elaborate step that takes place only if the first stage
succeeds. During the normal usage the system offers a series of panels,
being the first the filtering panel shown in figure 2.
Here at the left is shown the list of documents retrieved by the search
engine given the user query. each document is detailed in the right panel,
where the filtering results are also reported.
For an easier usage the system automatically sorts the document lists
so to help the user locating the best documents. The user browses the needed
documents by double-clicking on them, and then he can express a simple
feedback (as seen in the up-right window corner) among three different
values: very good, good or bad, in order to ease the burden on the user
as recomended in [morshi:96]. In this way the
system can modify her/his user model accordingly to user's preferences.
Furthermore, following [mulnig:96] a system objects
browser has been provided in order to allow the user to inspect all the
system's data structures with an effective graphical interface to shorten
the semantic gap between the user and the system. In the next section the
user modeling component is presented.
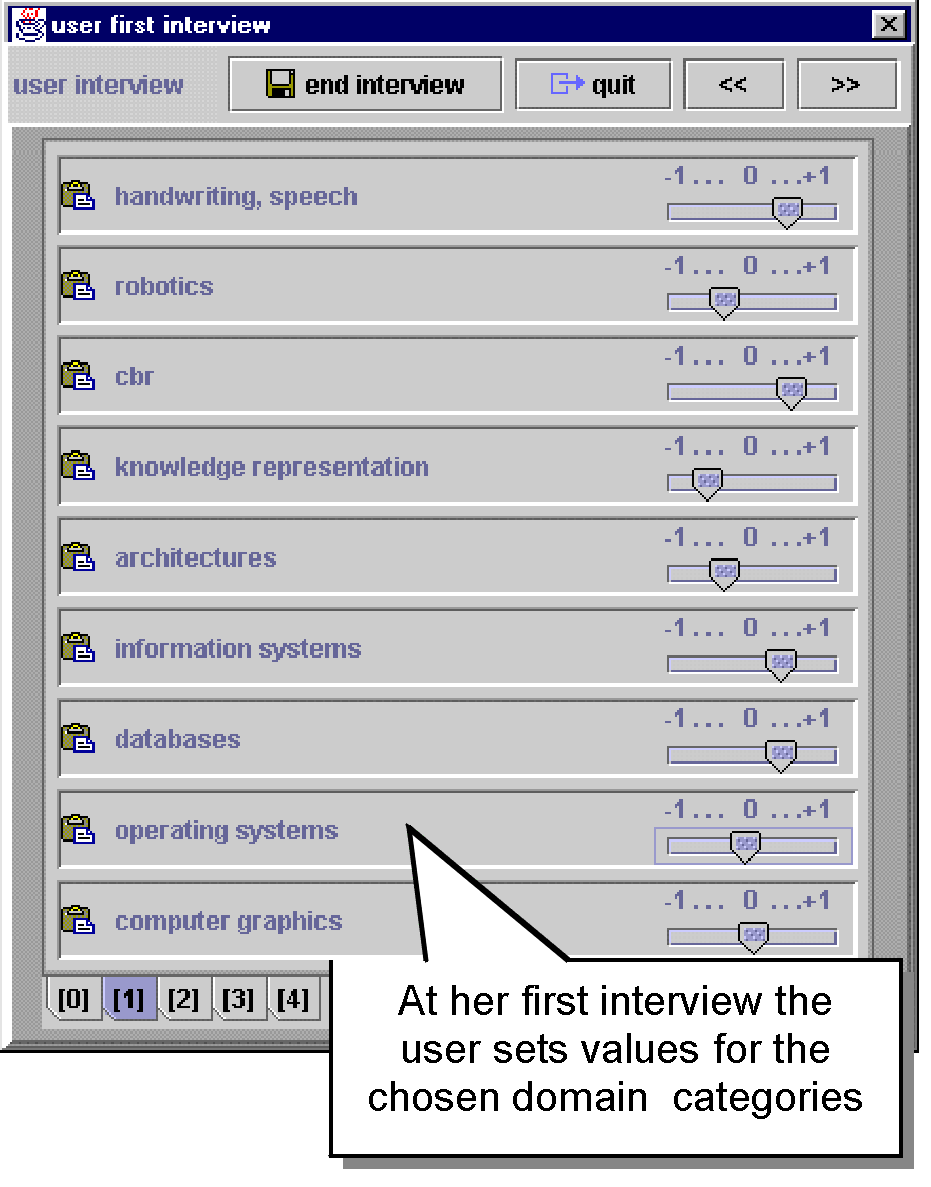

Figure 2. On the left, a screenshot from the interview to a new user (full size),
on the right the system query interface (full size).
3. The User Modeling Component
The user modeling process entails identifying the current user, retrieving
the relevant User Model (or performing a preliminary interview to create
one if none exists) then updating the model on the basis of how users interact
with the system and, lastly, furnishing data to answer explicit requests
about the user made by the host system. Our User Modeling subsystem like
other systems proposed in literature (see, for example, [Tasso:94]
), extends its beliefs about the user by relying on a set of stereotypes.
A stereotype is the formal description of a prototypical user of
a given kind [Rich:83]. Stereotyping is a way of
default reasoning about the user: by classifying the user we exploit a
lot of default information we have on that class of users. This information
may be revised later on by the system (inference activity, consistency
checking) when it gets more accurate knowledge about user's interests.
The reader interested in details about the inference mechanisms used to
build the user model can look at [ewcbr:98]. In
the user model are gathered the following items:
-
A content vector, that is an array of values that represents the information
content suitable for the Vector space model matching, as explained in
4.; with paired justifications (They express the provenience of that
element, if from initial interview or the current active stereotype, or
feedback, etc.)
Moreover, changes to the User Model are regulated using a fixed hierarchy,
so that lower items in the hierarchy cannot overwrite the values set by
higher items. For example an element modified by the user feedback is not
affected by changes from the stereotypes, etc.
-
A list of currently active contexts. Contexts are initializated all the
same for every user that has a non-zero value in her/his user model content
vector for each cluster having one or more non-null contexts. Then these
contexts are copied in the user's model and evolves indipendently according
to the single user history.
-
A list of the currently active stereotypes.
-
A set of user keywords each weighted with a value representing its actual
importance for the user. This elements are dinamically updated, inserted
or deleted after the user feedback,
not like the content vector's elements that are build
once for all and only changes in weigthing are possible.
4. The Information Filtering Component
The Information Filtering task has been a major research field since the
last ten years and is constantly growing thanks to the huge development
of the Internet. For a brief introduction to the field see the classical
[Belkin:92]. The approach used in this work is
to combine together different contributes to the final filtering score.
The difference with the classical vector approach lies in the
objects that make up the vector elements. Practically a hash mapping is used to map
words from documents in vector elements; once we obtain this transformation
the classical vector space model is used, not considering anymore the items
within the vector elements. Next we introduce this data structure.
4.1 The cluster vector
The Vector Space model (see [Salton:83]) has been
kept as a basis thanks to its very well known reliability and room for
improvement as constantly reported in the literature. The elements the
vector is made up with are sets (called clusters)
of pairs (term,context), with term
a word and context an object whose purpose is to disambiguate possibly
ambiguous terms using words before and after that word [2](see
[Xu:97]). For instance, the term network can
assume different meanings depending on the context where it is used. A
naive IF system can assume that a document about neural networks
is relevant for a query on computer networks. The clusters vector
is build once for all during an initial phase of knowledge extraction from
a corpus of documents on a particular domain. Also in this phase all the
contexts are created examining each repetition of the same term in the
corpus and measuring the distance between their contexts: if greater than
a threshold parameter the two instances of the same term are thought to
have different meaning, and their contexts kept separated, otherwise their
contexts are merged in one (of course this is the basic mechanism; great
improvements on efficiency are possible using simple practical assumptions).
To recap:
-
a Context is an object that keeps trace of words used when referring to
a particular instance of the ambiguous term in a text. Its use is motivated
by the assumption that terms related to different meaning of a single word
tend to occur together (see for example [Furnas:87]).
For instance, a simple implementation of such a data structure could be a weighted list of words.
-
a T-C pair is a pair of (term,context) used to disambiguate the
term applying its context on the input document.
-
a Cluster of T-C pairs is a set of such elements clustered together for
sinonimy. All the T-C pairs grouped together in a cluster are all the same
for the system. This mechanism allows for simplification while the use
of T-C pairs instead of simple terms gives higher precision to the clustering
mechanism.
4.2 Document Representation
Referring to the figure 3, detailing the document
processing module (a part of the External Retriever in the main architecture
in figure 1), every text document in input is firstly
transformed in a list of words obtained selecting only those which are
not present in a list of useless words (also known as a stoplist). Then
the words are matched against the term dictionary (this data structure
is built during the domain learning phase and is needed here to access
the idf, and other values for vector weigthing. To weigh the elements
we use the standard tf idf product, with tf the term
frequency in the document, and idf=log(n/df(i)) with n the
number of documents in the collection and df(i) the number of documents
in the collection who contain the word i, and pointers are obtained
to words known to the system. Then each term is disambiguated using the
known contexts for that term as explained in 4.2
. For instance, if the system has three different contexts associated with
a single word the disambiguation step produces three values, representing
the degree of fitness of that word occurence in the incoming text and the
given context. In step (4) each pair (term,context) from the input
document contributes to its belonging cluster weight with the values calculates
in the third step. At the end of the process from the initial text document
(e.g. in a HTML format) we have an array of values, each one for a cluster
of (term,context) pairs.
4.3 A Case-Based Approach to Information Filtering
A possible case-based approach to the selection of the most suited documents,
on the basis of the model of a particular user is introduced, described
in two main steps: (i) the Document Categorization (retrieval phase) and
(ii) the Score Refinement (adaptation phase).
The case library contains the old cases (obtained from the corpus
documents, in this first case in the
domain of computer science, chosen for being well-known and for the easyness
in finding documents) in the form of frames, whose slots contain
the <document representation,old solution> pairs. The old solution should
be the "score" of the old document according to a given User Model.Since
it is not feasible to represent the document score for each possible User
Model, we have chosen to represent the "solution" part of the old cases
as the category of the document.
The categorization module takes as input the same type of weights vector
of the filtering module, but with different clusters, because it needs
to match different features like authors, type of documents, etc. in the
incoming document. When the system is presented with a pattern of attributes
relative to the particular document, the indexing module tries to find
the old case that more closely matches (according to a specific metric)
the new case. The selected old case contains the relevant information useful
for classifying the document, i.e. the most suited category (or categories).
4.4 The filtering mechanism
To map the array of values - one for each category - coming as the categorization
module output into stereotypes, a matrix is used, with each element representing
an importance weight for that category in the given stereotype crossing
the matrix coloumns of the currently active stereotypes (one or more coloumns)
with the highest category value (one row of this matrix) .
The approach just described entails the definition of a metric to be
used in the indexing module. The problem is that this sort of classification
must be made in presence of incomplete and contradictory information. Our
proposed solution, consists in the use a function-replacing hybrid, where
an artificial neural network implements (i.e., is functionally equivalent
to) the part represented in figure 3. The
old cases present in the library of cases have been gathered from a domain
expert, and have been used as training records for training the neural
network. The knowledge of the Case Library is therefore represented in
a monolytic way into the weights of the network. Referring to the same
figure, the network replaces the indexing metric with a mechanism of generalisation
typical of these objects.
The filtering mechanism is described in figure 3.
For the current document the categorization module returns a score based
on its output and the list of active stereotypes present in the user model.
Only if the first stage returns a score higher than a given threshold the
second step takes place. Three different modules process the document (represented
differently for each module) returning three scores that combined linearly
with given weights make up the final score. The three different modules
work indipendently each one performing the filtering based on a different
perspective [3]:
-
The vector filter module transforms the document in an array of
values that maps on the Clusters array as described in 4.1.
This kind of filtering is performed using the standard techinques in the
IR field The query module uses a list of words representation of the document
and essentially counts the occurrences of the terms in the user query.
Despite it may seems redundant when using the system coupled with
a search engine with the user query posted on it.
-
The user keywords module matches each document word against a list
of weighted keywords in the user model producing the total normalized sum
of each occurring word's weight.
-
The user query module matches each document word against the words in
the query.
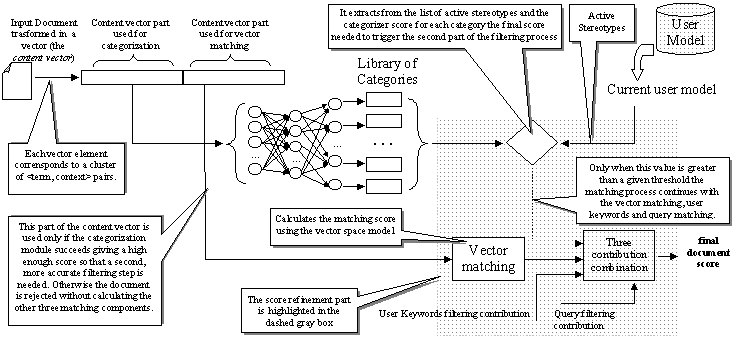
Figure 3. The Process of Score Refinement highlighted in the dashed grey
box. (full size)
5. Empirical Evaluation
A first evaluation of our system has been conducted through real-time access
to the World Wide Web. This activity has been performed as a matter of a preliminary
testing and a more extensive evaluation is needed, using a better comparison parameter
than AltaVista (that is not user-adaptive).
During the tests, one user has searched various kinds of information
concerning his interests (15 queries) on the Web. He has personally analyzed
all filtered documents giving the relative relevance feedback to the system.
After each filtering process we have obtained the rank ordered list of
the documents, given by the user. Then the following distance function,
between the AltaVista ordering and the system ordering has been computed
(following [Newell]):
D(x,y) = sum iN=0 Zi(x,y)
Where Zi = (|wii - wjj||xi
= yj), and wi =(N-i)2/N2. With
x, y vectors representing the rank ordered lists to be compared and N is
the number of the analyzed documents.
No Precision/Recall measurements were made, only document rankings were measured.
The difference between the system and AltaVista samples have been evaluated
using a non-parametric (or distribution-free) statistics (the
Wilcoxon Signed-Rank test [Wilcoxon] where the
reader is referred to for more detail concerning distribution-free
statistics). Finally, the analysis of the statistical results have been
performed to draw the statistical conclusion and the research conclusion.
The null hypothesis H0 in our experiment is the following: ``There
is no difference in performance between our system and AltaVista, measured
in terms of document ranking (i.e., the statistical populations concerning
the document ordering are the same)''. The alternative hypothesis H1
is: ``The differences observed between the distributions of the document
ranking are not due to chance but are due to the difference between
the populations to which they belong''. The results of the Wilcoxon test
are shown in Table 1. In the first row, the numerical values for the Wilcoxon
T+ parameter (the Wilcoxon valuator, see [Wilcoxon])
for the distance function is shown. In the second row the calculated probability
is presented. It is less than the significance level we set to 0.05
at the beginning of the experiment.
Therefore, we can conclude that, the null hypothesis H0
can be rejected and the alternative hypothesis H1 can be accepted.
This means that the differences observed from the sample sets are not
due to chance, but to different underlying distributions to which they
belong. The above statistical results support our choice of using a case-based
approach to user modeling for adaptive systems.
|
Distance Function
|
|
T+
|
90
|
|
Pr (T+>c)
|
0.0473
|
|
H0
|
rejected
|
|
H1
|
corroborated
|
Table 1
Wilcoxon Test results.
6. Conclusions
In this paper we have described a Case-based approach to the construction
of a Information Filtering system, capable of selecting and ordering HTML/text
documents collected from the Web, according to the "information needs"
of the User, represented in a User Model. Our system is based on a hybrid
arcitecture, where an artificial neural network is integrated into a case-based
reasoner. One advantage of this architecture is the inherent fault tolerance
to noise in data representing user behavior, which allows the system to
``gracefully degrade''.
The experiments have shown that, thanks to the case-based User Modeling
component, our Information Filtering system improves the capabilities of
AltaVista by more than 30%. In our work, we have turned to statistics to
analyze the system behaviour, and demonstrated that the system performance
"is not due to chance''.
A more extensive test of the system has been planned as a future work.
We have also planned to develop and evaluate further features with the
goal of improving the performance of both modeling and filtering processes.
As for the modeling process, we are improving the modeling capabilities
of the users by using a dynamic updating process of the user model. As
far as the filtering process is concerned, we are integrating the query
modality with the surfing modality to obtain a system able to autonomously
retrieve and filter documents.
References
-
[um:97] Ambrosini, L., Cirillo, V. and Micarelli, A.: A Hybrid Architecture
for User-Adapted Information Filtering on the World Wide Web. Proc. of
The 6th International Conference on User Modeling UM-97, Chia Laguna, Sardinia,
Italy, June 1997.
-
[Belkin:92] Belkin, N.J., and Croft, W.B.: Information Filtering
and Information Retrieval: Two sides of the Same Coin?. Communications
of the ACM,35(12), 1992, pp. 29-38.
-
[Tasso:94] Brainik, G. and Tasso, C.: A shell for developing
non-monotonic user modeling systems. International Journal of Human-Computer
Studies, 40, 1994, pp. 31-62.
-
[Furnas:87] Furnas, G.W., Landauer, T.K., Gomez, L.M. and Dumais,
S.T.: The Vocabulary Problem in Human-System Communication. Communications
of the ACM, 30(11), 1987, pp. 964-971.
-
[Haykin:94] Haykin, S. Neural Networks - A Comprehensive Foundation.
Prentice Hall International, 1994.
-
[kobsa:89] Kobsa, A. and Wahlster, W. (eds.): User Models in
Dialog Systems. Springer-Verlag, 1989.
-
[ewcbr:98] Micarelli, A., Sciarrone, F., Ambrosini, L. e Cirillo,
V.:``A Case-Based Approach to User Modeling''. In: B. Smyth e P. Cunningham
(eds.) Advances in Case-Based Reasoning, Proc. of EWCBR-98, Lecture Notes
in Artificial Intelligence, 1488, Springer-Verlag, Berlin, 1998,
pp. 310-321.
-
[mulnig:96] Mulhem, P. and Nigay, L. : Interactive Information
Retrieval Systems.Proc. of SIGIR 96, August 1996, Zurich, Switzerland,
pp 326-333.
-
[morshi:96] Morita, M. and Shinoda, Y. : Information Filtering
Based on User Behaviour Analysis and Best Match Text Retrieval. Japan Advanced
Inst. of Science and Technology Techincal Report, 15 Asahi-dai, Tatsunokuchi,Ishikawa
923-12 Japan
-
[Newell] Newell, S.C.: User Models and filtering Agents for
improved Internet information retrieval. User Modeling and User-Adapted
interaction, 7, 1997,pp. 223-237.
-
[Rich:83] Rich, E.: User are Individuals: Individualizing User
Models. International Journal of Man-Machine Studies, 18, 1983,
pp. 199-214.
-
[Salton:83] Salton, G. and McGill, M.J.: Introduction to Modern
Information Retrieval. McGraw-Hill Publishing Company, NewYork, NY, 1983.
-
[xu:97] Xu, J.: Solving the Word Mismatch Problem Through Automatic
Text Analysis. PhD Dissertation, Dept. of Computer Science, University
of Massachussets, Amherst, May 1997.
-
[Wilcoxon] Wilcoxon, F: Probability Tables for individual Comparisons
by Ranking Methods. Biometrics, 3,1947, pp.119-122.
Notes:
-
Throughout all the system the values used are ranging
from -1 (dislike) to +1 (like) if not otherwise specified.
-
Usually the context field is empty because
very few are the potentially ambiguous terms encountered during filtering.
-
Each module sharing a common mechanism for weighting
words with their actual importance in the document -for instance, words
appearing in the title in a HTML page are considered more important than
words in a paragraph.