The concept of Habitable Interfaces aims to bridge the knowledge gap by providing kinds of representations and the interaction with these representations that are based on domain knowledge. Habitable Interfaces will allow the organising of currently disparate archives into cohesive domain specific federations of information resources.
To approach designing Habitable Interfaces we propose a model of communication and a criterion.
There are several ongoing efforts worldwide aimed at designing federated systems as well as data warehouses.Some examples are [1, 4, 5, 6, 14]. Most of this work is being done on combining data and solving technological issues of creating federated systems. Although having resources readily accessible is a necessary condition, the user interface makes a difference between a collection of independent information resources and a federated system.
Van der Vet (2000) proposed a research environment to alleviate some of the issues of accessing web-based information resources.
As we noted above, there are many organisations maintaining information systems, and their number grows by the day (see, for example, an overview of information resources in molecular biology in [12]). Individual research groups generally will want to leave maintenance of these resources to the groups who created them. The organisation of the access to existing resources should better be based on federating these resources rather than on integrating them into monolithic systems [8].
When federating information resources a number of high level issues should be addressed:
Building federated systems requires a
design of the user interfaces
that will allow users to utilise available information effectively and
efficiently. Existing approaches to the design may not fit the scale of
the federated systems.
Perhaps, the most important issue in creating a federated system, is the gap between a variety of possible views and classifications of the same facts and rules that constitute knowledge, on the one hand and the limited representation that a designer can show to the user on the other hand. In the following part, we consider some issues of this gap in more detail.
Interaction of the user with the system and representing information about the content of a federated system are the most relevant topics for this paper. This brings us to the concept of Habitable Interface.
Federating information resources brings up the issue of the gap between varieties of views on information stored in an archive and the necessarily limited design of the archive. Further, we argue that the gap is inherent in the communication process and calls for new approaches.
Scientists are engaged in a knowledge discovery process. Knowledge is accumulated by collecting data. Collecting data requires a model that serves the purpose of practical guidance. Knowledge discovery is a collective effort, and a collective effort needs communication. In communication, researchers have generally different roles of authors and readers [13]. Given the variety of purposes that knowledge can be applied to, and the variety of data models, it is next to inevitable that there is a mismatch between the reader’s and the author’s data model. The situation worsens, when there are many readers and many authors who are trying to communicate on similar issues.
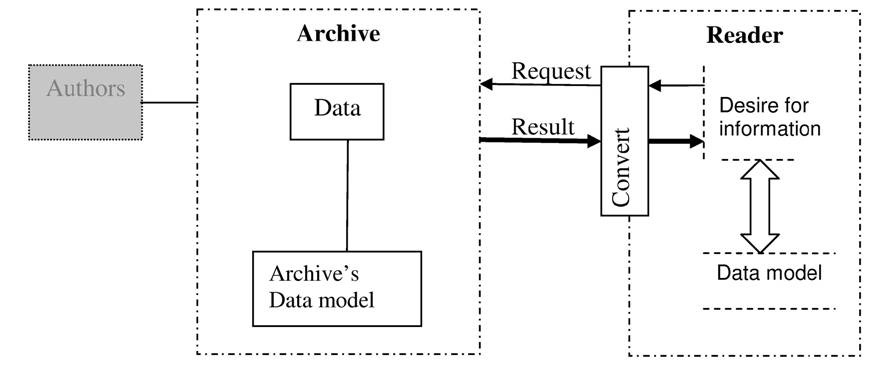
The archive can be perceived as an intermediary between authors and readers. Building an archive requires yet another data model (Figure 1). Differences between an archive’s data model and authors’ data models are not an obstacle for communication as it is only a question of converting known data using known data models.
Figure 1. Communication between archive and reader
But for readers the situation is different. Readers do not need to know the archive data model and they do not want to know the archive data model, as it does not fit their mental frame. As a consequence, there is a gap between what we call desire (expressing what information the reader wants to know), on the one hand, and need (referring to the information in the archive’s terms), on the other hand.
To fill the gap, an archive could convert data into a form required by readers. Multiplicity and dynamics of readers’ interests present too great a challenge for designers of archives and in principle, even the best study of requirements would not provide a uniform representation of the readers’ interests. Indeed, there is no average reader and there are many different archives.
Habitable Interfaces can help users to convert their desires for information into information needs that are then being communicated to the existing information resources. To arrive at an approach to designing Habitable Interfaces we start from a high-level model of communication between the reader and the archive. This model is rooted in other models proposed in the literature on Information Seeking and Information Retrieval: there are several overviews of the models and the concept of information in general (see for example [2, 10]). Here we would like to briefly consider the model proposed by R.S. Taylor [15] who describes the process of asking questions as starting from the ‘visceral need’:
The model suggests that users formulate a query in several steps. In later experiments [3] the last three steps were reportedly observed. But Taylor’s model does not explain how the visceral need is being converted into a compromised need. We believe that this conversion depends on the design of the retrieval system. An experimental investigation on such models has to generalize beyond the design of the system used in the investigation. In other words if the system design implies certain behaviour of the user it is likely to induce such a behaviour. For example with some interfaces, the readers have to explore the archive, with others they have to know the terms used in the archive before they can search for the desired information.
The significance of the Taylor’s model for Habitable Interfaces is that it postulates that a request to the archive is a result of converting a particular ‘inadequacy’ in a reader’s knowledge about some topic.
We add to this model of communication a model of the system. This allows stating a hypothesis about the system design that can be validated using empirical data.
To show how our model can be constructed we consider the communication process that takes place between the reader and an archive.
First, before starting the communication process, the reader has a certain desire for information. The word ‘desire’ implies a strong intention or aim. It is in contrast with the ‘need’ that is in general defined as a lack of something requisite or useful. Figure 2 shows this distinction from a number of viewpoints.
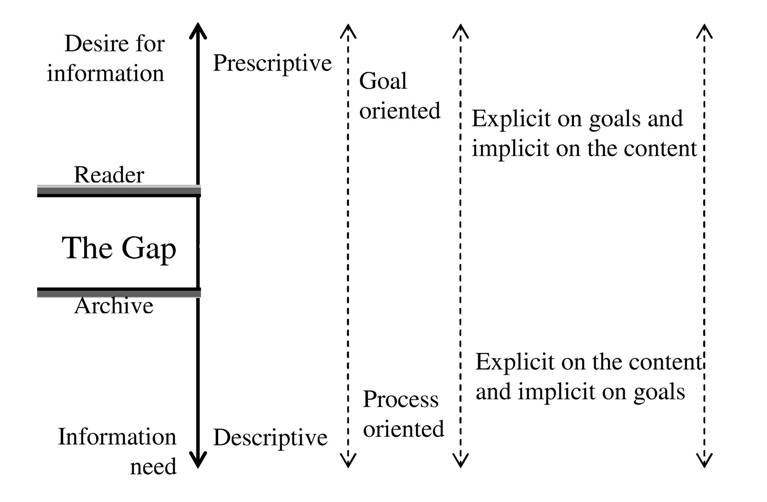
Figure 2. Distinction between desires and needs. There is a gap if the reader and the archive are at the different levels.
Based on the above we arrive at the
following characteristics of the
model of communication between reader and federated archive:
This model is depicted in Figure 3. Figure 3 also shows the way the information resources can be organised into a federated archive. An important question to be answered based on this model is the design of the “Unravel” and “Combine” functions. “Unravel” function presents to the reader what is available in the federated archive and allows building a comprehensive set of queries. In the federated archive, the query has to be “Translated” into requests to individual resources, since the internal representation of the federated archive differs from that of an individual resource. The results returned by the resources might need translation, too. Furthermore, these results must be combined into a single representation for the reader. However, the particular implementation would require answers to questions such as:
Our model suggests that the representations should be based on the domain knowledge and the interaction with these representations should be designed so that it requires minimal knowledge of the system.
The design of these functions serves to
reduce the requirements on
the reader’s knowledge about the system, and to improve the efficacy
and efficiency of the communication.
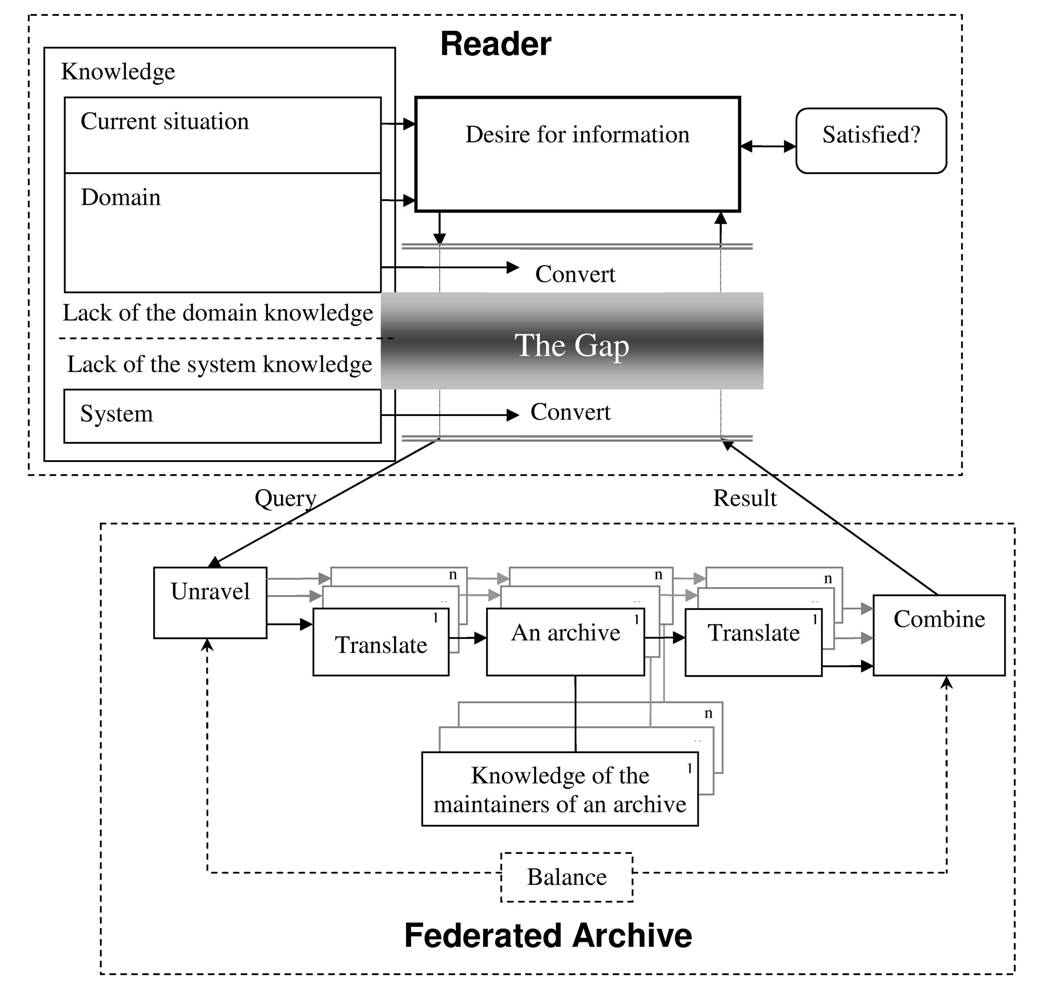
Figure 3. A model of Habitable Interfaces
For the high-level model to be applicable in designing a federated archive, it needs to be empirically validated. Such an evaluation can only be based on a priori agreed criteria and a method for evaluation. We argue that trust is a good indicator of the quality of the scientific communication that takes place and can be assessed using a mix of quantitative and qualitative methods.
In their communication, scientists are sharing with and delegating to the archive some of their tasks. In this perspective the reader, the trustor, should be able to trust the archive, the trustee, in this process of communication. This level of trust is posed to be a good indicator of the quality of information exchange. More on the relation of trust to scientific communication can be found in [9] and to information science and technology in [11].
On top of the complexity of the system there is a gap between the desires the users have and the needs that are supported by the systems.
The concept of Habitable Interfaces aims at helping the user to bridge this gap by means of incorporating the domain knowledge into representation and interaction.
At present, we work on the empirical validation of the model of Habitable Interfaces. The criteria of the validation will be based on the level of the user’s trust in a federated system.
In addition, we would like to explore how intelligent agents may support the user in carrying out routine but specific tasks.