Figure 1 - Course structure
D. Pilar da Silva, R. Van Durm, E. Duval1, H. Olivié
Departement Computerwetenschappen, Katholieke Universiteit Leuven, Leuven, Belgium
E-mail: {Denise.PilarDaSilva, Rafael.VanDurm, Erik.Duval, Olivie}@cs.kuleuven.ac.be
This paper presents ongoing research and development on creating adaptive background material for a last year university course on 'multimedia modeling and programming', hereafter called the course. The course is organized around concepts, which are explained by documents. Documents and hypermedia links are stored in a database. Concepts are linked to documents and to other concepts. Each document has an associated level of difficulty. The student is guided towards appropriate documents based on information about his knowledge of each concept.
Adaptive hypermedia systems (AHS) instantiate a relatively recent area of research, integrating two distinct technologies in computer assisted instruction, Intelligent Tutoring Systems and Hypermedia Systems. This is in effect a combination of two opposed approaches to computer assisted learning: the more directive tutor-centered style of traditional AI based systems and the flexible student centered browsing approach of a hypermedia system [Eklund 96].
Adaptive hypermedia systems build a model of the individual user, in order to adapt documents and links to that user. The goal is to personalize hypermedia.
Users with different goals and knowledge may be interested in different pieces of information and may use different links for navigation. Irrelevant information and links just overload their working memories and screen [Brusilovsky 96].
In order to overcome this problem it is possible to use information about particular users represented in a user model and then adapt the content and/or the links to be presented to that user.
The adaptation at content level is called adaptive presentation, while adaptive navigation support is based on the adaptation of the links from regular documents, indexes and maps (also called link-level adaptation).
The most popular area for Adaptive Hypermedia research is educational hypermedia. The scope is generally a course where the student goal is to learn all or most of the material. However, the learning goal can be differentiated among different students according to both their expectations with respect to the course and their knowledge about the subject being taught, the latter being the most important user feature in educational hypermedia [Brusilovsky 96]. There can be novice students that need direct guidance to find their way through the hyperspace, advanced learners, who would rather start with more complex information, and there can also be occasional users, who look for specific topics.
In the following sections we shall present the structure of the course and how this structure contributes to our approach to provide adaptiveness. Before analyzing our approach we will also give some background information on existing adaptive navigation techniques. Section 3 is dedicated to the course structure. In section 4 we describe how and on which grounds the adaptiveness is provided in our approach. The implementation issues are presented in section 5. In section 6, we discuss the current situation, the drawbacks we have encountered as well as possible directions and finally in section 7 we come to our conclusions.
According to [Brusilovsky 96] there are several goals that can be achieved with adaptive navigation support techniques, though they are not clearly distinct:
Such adaptive navigation techniques comprehend:
Most of the existing Adaptive Hypermedia (AH) systems use link hiding or link annotation in order to provide adaptive navigation support. Both techniques are very efficient and are presented in the next two sections.
2.1 Link Hiding
Link hiding is currently the most frequently used technique for adaptive navigation support. The idea is to restrict the navigation space by hiding links that do not lead to "relevant" pages, i.e. not related to the user's current goal or not ready to be seen. All kinds of links can be adapted according to this scheme by real hiding or by displaying hot words as normal text.
Hiding can help to support both local and global orientation. Local orientation is achieved when, by limiting the number of navigation opportunities to reduce cognitive overload, it enables the users to focus on analyzing the most relevant links. On the other hand, by hiding links, the size of the visible hyperspace is reduced and thus, global orientation is simplified.
The courseware on Hypermedia Structures and Systems (2L670) from the Eindhoven University of Technology is a good example of link hiding. This course uses a system they developed to track student progress and based on that, generate document and link structure adapted to each particular student. Links to nodes that are no longer relevant/necessary or links to information that the student is not yet ready to access are either physically removed or displayed as normal text [De Bra 97].
2.2 Link Annotation
Adaptive annotation is the augmentation of links with some form of comments, which inform the user about the current state of the nodes behind the annotated links. The annotations can be either textual or visual and can be used with all possible forms of links, like for instance, indexes or contextual links.
Link annotation can also be used to support local orientation by providing additional information about the nodes available from the current node. In order to provide global orientation support, annotation of links can function as a landmark, i.e., keep the same annotation for a node when the user look at it from different positions in the hyperspace.
Both hiding and annotation can help to provide local guidance, that is, to help the user to make one navigation step by suggesting the most relevant links to follow from the current node.
Interbook illustrates the use of link annotation [Brusilovsky 96b]. It is a tool for authoring and delivering adaptive electronic textbooks on the WWW. For each registered user, an Interbook server maintains an individual model of the user and applies it to provide adaptive guidance, navigation support and help. In order to provide adaptation, Interbook uses three kinds of link annotation:
Adaptive annotation is done by means of visual cues to show the type and the educational state of each link, which can have the following values: "known to the user", "ready to be learned", "not yet ready to be learned".
2.3 Other techniques
There are other techniques to provide adaptive navigation support, such as direct guidance, sorting, and map adaptation. We believe that these techniques are not the most appropriate ones for educational purposes because they can lead to incorrect mental maps, and so we are not going to elaborate on them. Sorting, for example, makes the order of links non-stable, i.e. it may be different each time the user accesses a page. Some recent research cited in [Brusilovsky 96] has already proved that stable order in menus is important for novice users. Besides, it can only be used with non-contextual links.
A primary concern for educational hypertext is the definition of an appropriate structure so that a student can easily and naturally find the most relevant information depending on his/her needs.
Our approach aims at providing adaptive navigation support. With this purpose we rely on typed nodes and typed and weighted links to represent the structure of the course, which is organized around concepts explained by a set of documents.
Links between concepts represent semantic interrelationships. At present, we consider only two link types for the concept-concept relationship: is_prereq_of and is_specialized_by. We plan to augment the model in the future with other link types such as is_related_to, is_similar_to and contrasts_with, since we believe it will be useful for students who learn better through comparisons. Links between concepts and documents will also be typed in order to include adaptive presentation, though this facility has not been implemented yet.
The documents are multimedia objects, such as text segments, static figures or interactive demonstrations. The URL of these documents is stored in a database. Each document has an associated level of difficulty with respect to the concept it belongs to, which varies from 0 to 99, where a higher weight means 'more difficult'.
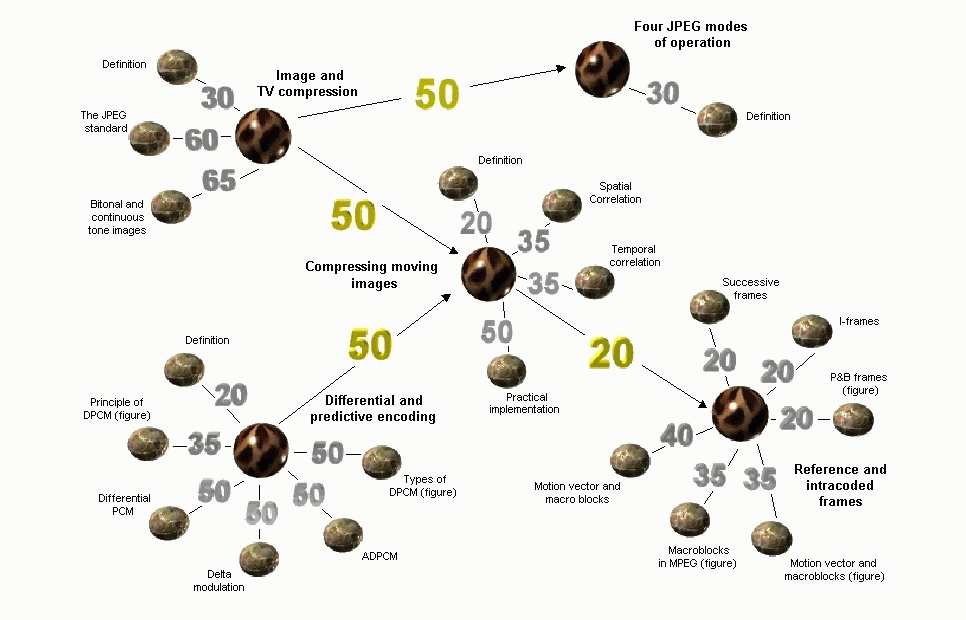
Figure 1 - Course structure
The course structure can be better understood through Figure 1. Concepts are represented by large circles and documents by small ones. A document explains the concept it is linked to. The label associated to the link between a document and a concept indicates the level-of-difficulty of this document with respect to this concept. Edges linking two concepts represent the relationship is_prerequisite_of and the labels correspond to the level_of_expertise a student must have for crossing the link between two concepts.
Figure 2 shows the login screen, i.e. the first screen all users get whenever they access the course. This is used to identify the user and access his/her user model.

Figure 2 - Login screen
The user model currently deals only with knowledge about each concept. We initialize student knowledge (or level of expertise) for a particular user as 0 for every concept [Calvi 97] and update this value after the student has visited a document related to the concept. We are aware that this is a rather naive approach, but we have adopted it for the time being because the course is intended for a last year university audience, which is assumed to be homogeneous. Of course, consider a text "known" after visiting a node is also a naïve assumption, but this leads us to a more complex problem - how to measure knowledge acquired on-line. We intend to solve this by applying tests tests afterwards.
The level of expertise determines the documents available to a student. Basic concepts, that have no prerequisites, can be accessed by a new student. Acquiring these basic concepts enables the student to consult documents related to more advanced concepts.
The current knowledge k of a student s about a particular concept c can be described as k(s,c) with 0 £ k(s,c) £ 99.
Associated to the is_prereq_of relationship between two concepts, there is a threshold t, that represents the minimal level of expertise a student must attain on the prerequisite in order to access the more advanced concept.
The set of relevant concepts RCs for a student can be defined by the rule:
RCs = { c | basic(c) Ú [ $ c': (c' is_prereq_of c) Ù ( k(s,c) ³ t(c', c) ) ]}
This means that a student can access basic concepts, as well as concepts whose prerequisites he/she masters sufficiently well.
The documents accessible to a particular student are those that belong to the set of relevant documents (RDs), defined as follows:
RDs = { d | explains(d,c) Ù c Î RCs Ù [(k(s,c) - d) £ diff_level(d) £ (k(s,c) + d)] }
Here, d represents a document and d is a constant. The above expression means that relevant documents are those that explain a relevant concept with an appropriate difficulty level (as defined by d).
When a student visits a document, his/her level of expertise is updated in the following way:
if d Î RDs Ù k(s,c) < diff_level(d)
then k(s,c) ¬ diff_level(d)
This simply means that in case the level of expertise for this student with respect to the current concept is not inferior to the difficulty level of the current document, then the level of expertise is updated with the difficulty level value.
The work described in [Signore 97] explores similar ideas in a non-educational application, where the user has more control (for instance with respect to the threshold value).
Currently, all information is stored in an Access database and dynamically translated into HTML. There are several approaches to do this, varying from the more traditional CGI approach to server-side includes and newer technologies like servlets. At the moment, we rely on the Active Server Page technology developed by Microsoft, but we intend to use a new approach we developed, where a Java based web server instantiates the necessary classes from a persistence layer [Hendrikx, Duval & Olivié 97]. The goal is to achieve better performance when not using the system locally, since running both the Web Server and the Access database on a PC makes it very slow to use the system from outside the university. The application will be tested soon with students at K.U.Leuven.
5.1 User Interface
The user interface makes use of HTML frames and Javascript. In Figure 3, we see what the user interface looks like. The frame on the upper-left contains the list of concepts that are available for this student at this particular moment, that is to say, the calculated set of relevant concepts. On the lower-left frame we display a list of clickable documents (the calculated set of relevant documents) that are available at this moment for the current concept and appropriate for the current user. Clicking on a document on this list brings its content to the frame on the right.

Figure 3 - User interface
At the moment we are working on the user-interface, which, we believe, plays a crucial role in an adaptive hypermedia system, especially in an educational framework. We are also defining the grounds to migrate to a Unix platform.
In the future, we want to elaborate the user model by including some cognitive characteristics, which are relevant for learning processes, like for instance cognitive style [Höök 96, Wilkinson 97], or reasoning abilities. We will enrich the prototype with stereotypes that will also be part of the user model. Thus, a student will only see the links that are associated with the stereotype representing his/her profile.
Another enhancement we are currently implementing is the dynamic drawing of local overview diagrams or concept maps that show the immediate neighborhood in order to help minimize cognitive overhead.
Tests can be easily accommodated in the model as simple documents, making it possible to evaluate any previous knowledge a student could have about the subject in order to allow him/her to skip known concepts. We can, as well, use those tests to assess and update the knowledge a student actually acquired when following the course.
A model for adaptive courseware navigation has been presented. The underlying domain structure around concepts, documents and semantic relationships, allows us to offer different navigational possibilities to different students based upon a user model, which is constantly updated while the student is accessing the course. We rely on the notion of typed nodes and typed and weighted links to represent the structure of the course. Concepts are related to other concepts through the is_prereq_of and is_specialized_by relationships, which also have an associated threshold that represent the minimal expertise a student must have for crossing the link between two concepts. A document explains a concept and has an associated level of difficulty, which is used to update user level of expertise about that concept. After a student accessed a document, the correspondent changes in the user model are reflected in the user interface, that is, relevant links are added to the screen and links that are no longer relevant are removed from it.
This model has been implemented by a prototype that actually carries out the desired adaptiveness but needs some improvements in the user-interface. However, running both the Web Server and the Access DBMS on a PC makes it very slow to access from outside the university. For this reason, we are planning to migrate the whole application to a server running on a Unix machine and convert our data to Oracle database through HOME, a new approach developed in our group.
[Brusilovsky 96] Brusilovsky, P., Methods and techniques of adaptive hypermedia. User Modeling and User-Adapted Interaction Journal Vol. 6, pp. 87-129, 1996.
[Brusilovsky 96b] Brusilovsky, P., Schwarz, E. and Weber, G. A Tool for Developing Adaptive Electronic Textbooks on WWW . WebNet'96 World Conference proceedings book. pp. 64-69 . 1996.
[Calvi 97] Calvi, L. Navigation and Disorientation: A Case Study. Journal of Educational Multimedia and Hypermedia. v. 6(3/4). pp. 305-320. 1997.
[Davis 95] Davis, H. To Embed or Not to Embed. Communications of the ACM, 38(8), pp. 108-9. August 1995.
[De Bra 97] De Bra, P. Teaching Through Adaptive Hypertext on the WWW. International Journal of Educational Telecommunications. pp. 163-179. August 1997.
[Eklund 96] Eklund, J., Zeilliger, R. Navigating the Web: Possibilities and Practicalities for Adaptive Navigation Support. Second Australian World Wide Web Conference (AusWeb96). Southern Cross University. Lismore. Australia. 1996.
[Hendrikx, Duval & Olivié 97] Hendrikx, K., Duval, E. & Olivié, H. HOME - The Next Generation. WebNet'97 World Conference. Toronto. Canada. November 1997.
[Höök 96] Höök, K. A Glass Box Approach to Adaptive Hypermedia. Ph.D. Diss. Stockholm Univ. October 1996.
[Signore 97] Signore, O. et al. Tailoring Web Pages to Users' Needs. Proc. of the workshop "Adaptive Systems and User Modeling on the WWW" - 6th International. Conference on User Modeling. June 1997. http://zeus.gmd.de/UM97/proceedings.html
[Wilkinson 97] Wilkinson, S. Document Structure, Individual Differences and the Learning Process. Poster at the 8th ACM Conference on Hypertext. April 1997.
The financial support of CNPq/Brazil for D. Pilar da Silva's scholarship is gratefully acknowledged. The Socrates program of the European Commission provided financial support for the elaboration of the courseware, in the framework of the EONT project (
http://hyperg.softlab.ntua.gr/EONT).1
Postdoctoral Fellow of the Fund for Scientific Research - Flanders (Belgium) (F.W.O.)