Basic concepts
Our framework is based on Russell and Wefald's
metareasoning decision theory (Russell & Wefald 1991). This
decision theory allows one to select between so-called 'internal
actions' and 'external actions', based on a notion of maximum
expected action utility (reflecting the
degree of 'usefulness'). Internal actions are, in our usage of
this theory, the search actions, whereas the external actions
are the decisions to retrieve particular objects. The expected
utility is based on the provider-estimated information for the
(query dependent) relevance and involved cost of the actions.
As executing an action costs time (and money) these estimates
need to be available prior to the execution of the best action.
While the search proceeds, the system explores unknown parts of
the information environment and updates its view accordingly.
When relevant information has been found, the system must decide
whether to retrieve it or continue searching trying to find 'better'
information (e.g. more relevant or cheaper). Because the cost
specified in the query refers to the total cost, the system continuously
needs to decide how much budget should be spent on searching and
how much on retrieving. This is the fundamental problem that we
tackle in our resource-limited retrieval strategy.
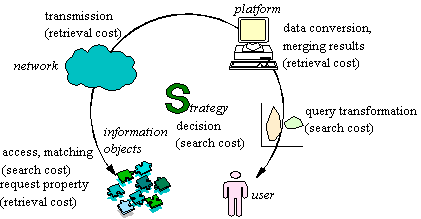
The search and retrieval cost in a real information environment are comprised of multiple cost aspects, see Figure 1. Although a retrieval system ultimately needs to handle all these cost aspects individually, we aggregated them into two categories of costs: search cost and retrieval cost.
Search cost
are all cost that are made when relevant information objects are
identified, given a user specified query. The retrieval cost
are all costs induced by retrieving, transporting, and/or presenting
the requested properties from the selected (most useful) information
objects to the user.
Query
In our approach a user specified query consists of different parts, viz. a retrieval expression, a starting expression, a filter expression, a ranking expression, and an optimising expression. Using an SQL like notation, this can textually be expressed as follows:
The retrieval expression states which properties of the filtered and ranked information objects the user wants to retrieve (and or present), e.g. 'title of the books'.
The starting expression states the potential starting point(s) from where the retrieval system should start searching.
The filter expression restricts the amount of potential suitable information objects to those objects that fulfil the constraints of the filter expression. These constraints may refer to individual information objects, e.g. minimum relevance of an object, but also to the search session, e.g. total cost < c, total time < t, or may restrict the amount of objects to be retrieved. A degree of importance can be attached to the constraints to indicate their strictness, e.g. via weights, priorities or the risk of overspending. In our current strategy, we have included a simple mechanism resulting in three strategy variants, viz. a cautious strategy, an opportunistic strategy, and a common strategy.
The ranking expression is used to determine the presentation order of the information objects satisfying the filter expression. It may include relevance and cost aspects. The filtering expression (e.g. value > threshold) can be used as ranking expression (using the value) when it is based on the same properties.
The optimising expression (or session utility function) specifies the 'optimal' selection of information objects that fulfils the constraints. See Figure 2 where, within the constrained area, a darker colour represents a more useful solution. When the objective function includes both time and money aspects they need to be combined. This requires a form of normalisation or transformation, e.g. assign 'monetary' cost to time, which is common in economics.
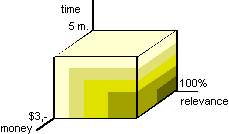
The cost aspects included in the constraints and objective function reflect the total cost, and not separately for retrieval cost and search cost. As users may have different constraint and objective functions, the retrieval system should be capable dealing with any (user-defined) constraint and objective function including queries like minimise the total cost for the search and retrieval of a fixed number of relevant information objects; maximise the amount of (the top most) relevant information objects for fixed costs; maximise the sum of relevance scores/the score-cost ratio (for a fixed number of relevant information objects) for fixed cost.
The user can thus specify what the 'optimal'
selection of information objects that fulfils the constraints
should be, for example to ask the system to maximise the sum of
the relevance of the retrieved results at a minimum cost.
The closer the results of the search are to this 'optimum', the
higher the utility of the search session
will be. It may be clear that when the search proceeds the current
session utility is likely to change because cost and time are
continuously being spent. This intuition forms the basis of our
strategy. The strategy looks like:
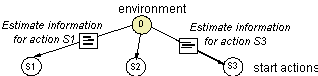
Determine start actions
For a large dynamic information environment it is very unlikely that the environment is completely known to the strategy. Furthermore, exhaustively searching all available collections within reasonable time seems not feasible. Hence, a strategy should determine where to start searching. The actual starting point for the strategy is the root of the 'action search graph', a virtual node representing the information environment the search is conducted in, see Figure 3. We assume that the strategy is aware of at least the access information (such as address and access mechanism) of the start (search) actions. This information is either provided by the query (in the FROM clause) or encoded in the strategy as default(s). In addition, other information (coverage, type, …) about the objects that are related to the action may also be available (can be stored from previous search results or obtained via polling, as is done by many Internet search engines). Nonetheless, due to the size and the dynamic nature of the information environment, it may not be worthwhile to maintain this information. When this information is not or only partially available, the strategy cannot determine the cost involved in executing an action nor the usefulness of an action.
The strategy may restrict itself to the fully labelled transitions or may actively acquire the missing information by accessing uninformed objects. Although additional (access) cost are made, this approach may eliminate unnecessary searches and hence save cost. We do not elaborate on this problem here, but assume now that the strategy only chooses among sufficiently informed actions.
Filtering actions
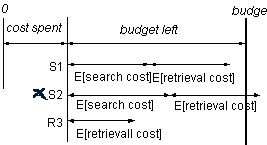
In step 2 the strategy removes all actions that do not satisfy the constraints specified in the query. This means that for each action that is not removed, it is estimated that it can be executed within the remaining time and money budget. The cost estimates need not necessarily be single valued (e.g. the average) but may consist of multiple values, like minimum, maximum etc., or in general be a probability distribution function. By supporting different strategy variants the risk of overspending can be controlled. The variants differ in action filtering, action selection and session termination. The strategy supports three different filter rules:
Because searching is only useful to a user when (a property of) a relevant information object is retrieved, not only the cost of a search action itself should satisfy the constraints but also the (estimated) remaining search cost to find a relevant information object as well as the (estimated) retrieval cost of this object. This means that only when a relevant object is expected to be found and can be retrieved within the constraints, the search action is acceptable. See for example Figure 4 where search action S1 and retrieval action R3 are acceptable whereas search action S2 will be filtered out.
Action utility
Given the estimations of the time, money, and relevance of different actions, the question remains how these different estimates can be combined into a single decision criterion. As the strategy should optimise the user formulated session utility function, we advocate to use this function to estimate the utility of individual actions. As action utility should only be based on the results and cost related to the particular action, the session utility function should be adapted to reflect the cost and relevance aspects of the individual actions. For example, suppose we have an session utility function: (sum of relevance)/(cost spent). Then the estimated utility of a search action j will thus be E[relevance object j]/(E[search cost] + E[retrieval cost]). And the estimated utility of retrieval action j is E[relevance object j]/E[retrieval cost].
These (query dependent) relevance and cost estimates can be obtained
prior to the execution of an action. As these estimations are
independent of the actions carried out by the strategy, the utility
of an action does not change. Hence, only the utility of new actions
need to be computed.
Action selection
It is natural that, when money and time aspects are taken into account, the outcome of a search depends on the order of the performed actions. In case there are multiple actions satisfying the constraints, the strategy needs to choose. Throughout the search the strategy continuously has to decide what action to carry out next. This 'best' action seems to be the one with the highest expected utility. Simply using the expected money cost in the computation of the utility works fine when a large number of searches are performed, e.g. for the search service provider, and these average cost are charged to the user. For a single search this is not satisfactory because the average does not reflect the real cost of the retrieved information object. From (Lomio 1985) we know that users are very cost sensitive and do not want to pay an unspecified amount of money for an unknown amount of data. Failures in estimating the costs in advance generally lead to complaints about the system. Instead of considering only the expected utility, different (measures of the) utility distribution can be used to cope with different variants of the strategy (e.g. cautious, common or opportunistic). For example in (Palay 1985) rules are described to select the most appropriate alternative when they are characterised by a minimum, average and maximum value for a chess game. The application of this approach in our context, assuming that the average, upper and lower bound utility scores are computed, leads to the following rules, each representing one of the three strategy variants:
Instead of using the upper bound, lower bound and average values,
one can use any (combination of) measurement(s) of the (multi-aspect)
utility distribution to compare the alternatives, e.g. a virtual
upper bound using the standard deviation, so that e.g. 95% of
the values are below this point.
Session Termination
It may be obvious that the session terminates
when no search or retrieval action passes the filter rule. When
the strategy still has actions to choose from, we use the relation
between the estimated action utility and session utility
as a stop criteria. We argue that the strategy should terminate
the search session when the estimated action utility of
the 'best' possible action is not higher than the current session
utility, illustrated in Figure 5. To use this rule the following
criterion should be met for each estimated action utility function:
when the estimated utility of an action is higher than the
current session utility and assuming perfect estimates, execution
of this action should increase the session utility.
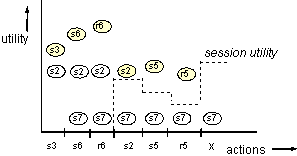
We show that in the example with a session utility function: (sum of relevance)/cost, that the action utility functions meet the above defined criterion. Let A denote a search session: a sequence of actions (A1 ... Ai); Aj is action j. Aj can also be denoted as Sj when Aj is a search action and Rj when Aj is a retrieval action. EU(Aj) is the estimated utility of action Aj; U(A) is the session utility and U(A.Aj) is the session utility after executing action Aj. It can be proven that when EU(Rj) > U(A) that U(A.Rj) > U(A) when relevance and cost estimates satisfy the above defined conditions. In our example U(A) = r/c (denoting session-relevance/session-cost) and EU(Rj) = rj/cj (denoting relevance of action Rj /cost of action Rj) then U(A.Rj) = (r+rj)/(c+cj). When rj/cj > r/c this implies that (r+rj)/(c+cj) > r/c. When Rj is the retrieval action included in the estimation of U(Sj) and perfect relevance and cost estimations are available, then U(Rj) > U(Sj), and thus U(Sj) > U(A). Hence U(A.Sj.Rj) > U(A).
Due to inaccurate estimations U(Rj) > U(Sj) may not be true. As the accuracy of the estimations is not known in advance and the utility of an action may be a probability distribution function, different (termination) rules can be applied reflecting different strategy's variants. We use the following rules:
When the best chosen action is carried out, the current view of
the information environment is updated accordingly and the strategy
continues the search session.
Estimation of cost and relevance
It is the responsibility of the information
provider to provide the (query dependent) estimates to the strategy.
This is vitally important for the effectiveness (in terms of recall
and precision) of the strategy. To get an idea how the estimates
can be obtained, we briefly sketch the ideas behind the mechanisms
of the ADMIRE information model (Velthausz, Bal & Eertink 1996),
that we use in our IR system. The ADMIRE model provides a general
framework for modelling any information, regardless of type, size
or abstraction level, including Web-based information environments.
Via a notion of different kinds of information objects and (informed)
relationships, it facilitates a gradually expanding action search
graph, with labelled transitions that can be used to estimate
the (query dependent) relevance and involved cost
of the actions.
Information objects in ADMIRE have various types of properties, namely raw data (sequence of elementary data units), format (representation of the raw data, e.g. MPEG), attribute (characterisation of the raw data and its format in relation to the external world, e.g. creation date), feature (a domain-independent representation of the raw data and format, e.g. colour histogram), and concept (a domain-dependent and format-independent semantic interpretation of the other property types). The property types are modelled in a three-layer hierarchy, Figure 6. The lowest layer is the data layer. It contains the raw data, format and attribute properties. All the properties in this layer are stored as they convey information that cannot be determined differently. The feature and concept layers contain information that can be determined (respectively via feature extraction and concept inference) using the properties of the lower layers and extraction algorithms (for features) and (domain) knowledge rules for concepts. As opposed to features, concepts are context dependent, different concepts can be inferred from the same lower layers. The context only influences the usefulness of particular features
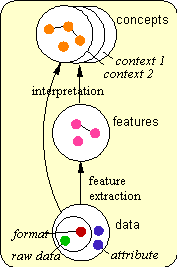
The problem is that the relevance of information objects is query
dependent and can only be determined when either the object is
accessed or fully indexed. Given the wide range of possible queries
in a large and dynamic environment, it is impractical to reuse
relevance estimations of previous searches nor fully index all
objects. The ADMIRE information model facilitates aggregation
and propagation of information that characterises reachable information
objects. The composite relationships in the object hierarchy enable
a bottom-up propagation and aggregation of the lower layered object
characterisations. This information can subsequently be used to
estimate the relevance of unexplored information objects.
In addition to estimating the relevance, an accurate estimation of the remaining search cost to find the requested information objects as well as the retrieval cost of these objects is needed. As the cost may (partly) depend on the query, the structure of the query (e.g. the operators, the requested number of objects etc.), can be used to estimate the remaining search and retrieval cost. Although the ADMIRE model has not been developed to support cost estimations, it can simply be extended using the bottom-up propagation and aggregation of cost-related information. Instead of the actual distribution function, derived measures such as average, minimum, maximum, variance, etc. can be used.
A potential problem with upwards propagation of information is
the topicality of the aggregated information. Since this information
is obtained prior to the actual search, changes in costs, adding
new or deleting information objects might not be directly reflected
in the aggregated information. Furthermore, a consequence of the
use of the aggregation methods is that the cost and relevance
estimates are independent of each other and therefore may lead
to inaccurate utility estimations.
Prototype
Our retrieval strategy needs to choose among potential interesting information objects (web-pages) to explore further or retrieve. This decision is among others based on the relevance estimation of a particular object. As our focus lies on impact of limited resources on the search process, and not on the quality of the matching, we use standard vector based keyword text-retrieval. The keywords are used as substitutes for the information object concept property. For non-textual information objects, the keywords are currently manually labeled. The frequency of the keywords is used to compute the object term weights. We use a standard term frequency weight scheme suitable for dynamic collections with varied vocabulary conform experimental evidence of (Salton, G., Buckley C., 1988).
The similarity between the 'concept query vector' and the 'information object concept vector' is computed using the well known cosine vector similarity measure that has been extensively used.
As within ADMIRE the information objects
have multiple properties, the relevance between an information
object and a query is not only determined by concept matching
but also influenced by the matching between the other query and
information object properties, i.e. attributes, formats and features.
The matching of these other properties in our prototype is currently
implemented using Boolean matching. This means that relevance
for an object is equivalent to the 'concept vector similarity'
if it satisfies the other requested properties (e.g. format is:
image or text), else it is not considered not to be relevant (score
= 0).
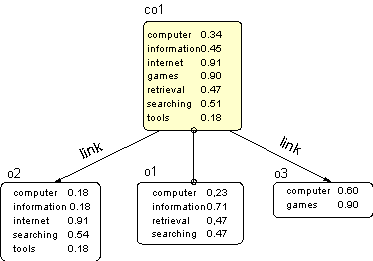
The use of summarised information to describe particular aspects of the lower layered nodes in a hierarchy, has also been reported in (Garcia-Molina, Gravano & Shivakumr 1996) for the content-characterisation for (hierarchical) databases containing textual documents. We have adapted some of their ideas and included them in our prototype for web-based information to provide vector based keyword text-retrieval. For composite information objects the (standard) term frequency does not refer to the number of occurrences of the term in the object but the number of sub-documents (sub-objects) it occurs is. This enables us to use the same matching principle regardless the information object. We assume that the weight of a term is uniformly distributed over all related objects (via sub-links and other links) that contain the term. This means that the object term weight is averaged over the number related objects containing the term. We illustrate this with an example, see Figure 7. The aggregated weight for the term 'computer' of composite object co1 is computed as follows: (0.18+0.23+0.6) / 3 = 0.34. Similar, the aggregated weight for the term 'information' = (0.18+0.71) / 2 = 0.45.
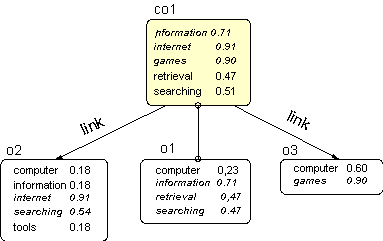
Applying this type of keyword aggregation may lead to a large list of different terms as it keeps track of each term that occurs in one of the related information objects. Especially when there are many links to other objects and multiple hierarchical levels. To make the keyword aggregation more similar to concept aggregation, as intended in ADMIRE, we introduce a filter. Only the most important terms of an object are taken into account during the aggregation process. What an important terms is can be defined in many ways. We consider a term to be important if the weight is equal or better than the average object term weight, see Figure 8.
Although the ADMIRE information model was not developed for hyperlinked information environments, we want to determine whether the ideas can be applied in web-based information environments. As these information environments are typically not hierarchical and are likely to contain (many) cycles, we need to adapt the aggregation and propagation process.
A quick view on the World Wide Web shows that it has a lot of hierarchical (sub)structures incorporated by the information providers, e.g. a home page can be seen as a root for a site. Based on this observation we assume that the authority that performs the aggregation process, assigns such root-page(s) or -site(s) from which a 'pseudo' hierarchical structure can be derived.
However, in the Web cycles do exist. Dealing with cycles during property propagation effectively implies cycle (membership) detection during the aggregation process. A simple approach is to simply skip those links that introduce a cycle. In this manner a directed a-cyclic graph is obtained and the standard aggregation process can be applied. The drawback of this method is that the decision of which links to skip, which is determined by the cycle avoidance algorithm, has effect on the aggregation results. Another, better but more time consuming approach, is to construct a directed a-cyclic graph for each node that is part of a cycle, and apply the standard aggregation process to the graph. Another approach is to consider nodes that are part of a cycle as a single 'virtual node' during the aggregation process. This results in one aggregation description for all objects of the cycle. A drawback of the latter approach is it may reduce the information structure to a few or even a single node when many cycles exists. Yet another approach that loosens hierarchical relationships to reachability relationships (object a is reachable from object b, either directly or via intermediate objects) is based on dynamic routing algorithms. As the links in a Web based information environment are unidirectional (from referring object to the referred object), pushing (or flooding) information from the referred object to the referring object(s) is not possible as the referred object does in general not know the identity of his referring object(s). This means that a kind of pull principle needs to be applied in the aggregation process.
Our approach treats a link that introduces a cycle, as a 'special'
link. This link is treated in the aggregation process in a similar
way as a link to an 'external' page (a page for which another
information provider is responsible). For these links only the
information of the referring page is taken into account and not
the information that is reachable via that page. The drawback
of this approach is that it may result in a different aggregation
result when another start page is used. This drawback is overcome
by aggregating information for each possible root page (assigned
by the provider) while re-using already aggregated information
whenever possible.
We illustrate this with an example. Assume that the following files are available of which some HTML files contain links to other files, Figure 9.
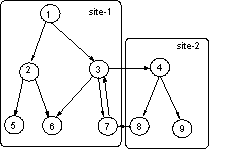
The corresponding ADMIRE information structures for the start pages 1.html and 4.html are presented in Figure 10. Remind that for the 'special' links (marked grey) only the direct reachable information is used in the aggregation process. HTML files that contain links to other files are considered as composite objects (indicated via an 'c') of the other files. From the ADMIRE viewpoint the content of the composite page is treated as a normal 'leaf text page object', thus without any links. In-lined objects, for example images, are treated as sub-objects of the composite pages in the aggregation process. This means that when concepts are inferred for the images, or as in our prototype manually labelled with keywords, these can be used in the relevance estimation of the composite object, i.e. the referring HTML page).
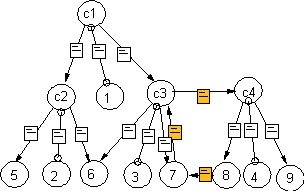
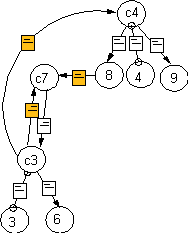
During the aggregation process not only information needed for the relevance estimation it collected, but also information is aggregated for estimating the remaining search cost and retrieval costs (time and money). This is done as follows:
We use (and aggregate) the size of information objects to estimate
the retrieval time. In the aggregation process we use the minimum,
average and maximum size of related information objects. In this
aggregation process the size of in-lined objects, i.e. images,
is added to object size of the composite object (the referring
web-page). The strategy computes the estimated retrieval time
taking the actual session's transmission performance (delay and
throughput) into account. For estimating the remaining search
time we use (and aggregate) the (minimum, average and maximum)
number of search steps (depending on the depth of the tree).
Evaluation
In our prototype we tested the algorithm on our own intranet to evaluate the principles behind the mechanism. We use individual pages to represent indexed websites (a broker principle; the main index contains references to other indexes and/or direct information collections). This allows us to test the ideas behind the mechanism in a relatively small and stable environment. In this environment we have complete control, and therefore are able to generate any amount of aggregated information next to our real data. In the Internet this is not possible, as no access to other people's web servers is, generally speaking, available.
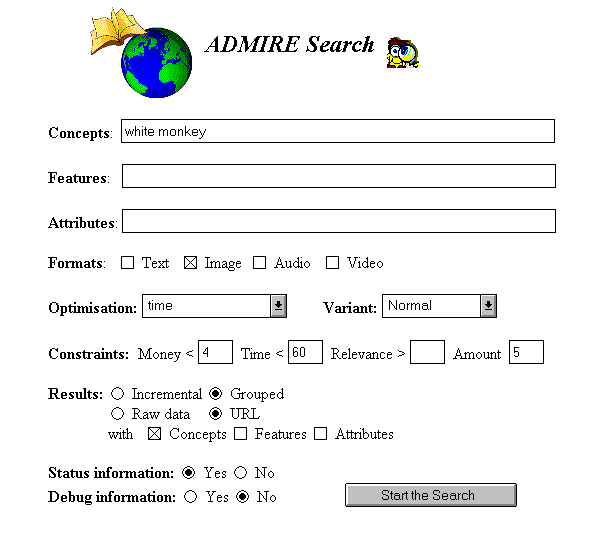
In the figures below screen dumps are given of our web-based prototype
query interface, Figure 11, and status information presented to
the user during the search session, Figure 12.
The evaluation is still ongoing. The approach is that we have
implemented several variations on the above mentioned strategy.
We evaluate this on differently structured information environments.
This evaluation will provide insight in the dominant factors that
influence the performance of this strategy.

Garcia-Molina H., Gravano L., Shivakumr N., 1996. Finding Document Copies Across Multiple Databases, In Proceedings of 4th Int. Conference on Parallel and distributed Information Systems, PDIS'96.
Lomio J.P.,1985 The high cost of NEXIS and what a searcher can do about it. Online 9(5):54-56.
Palay, A.J. 1985, Searching with probabilities. Ph.D. Thesis, Carnegie-Mellon University, Pittsburg
Russel S., Wefald E. Do the Right Thing, MIT Press, 1991
Salton, G., Buckley C., Term weighting approaches in automatic text retrieval. In Information Processing and Management, Vol. 24, pp 513-523, 1988
Velthausz, D.D., Bal, C.M.R., Eertink, E.H. A Multimedia Information Object Model for Information Disclosure. In Proceedings of the MMM'96, Third International Conference on MultiMedia Modelling, Toulouse, France, pp 289-304, 1996.
Velthausz, D.D., Eertink, E.H., Verhoosel, J.P.C. Schot, J. Resource-limited information retrieval in a distributed environment. In Proceedings of AAAI-97 Worksop Online Search, Providence, USA, pp 114-121, July 28, 1997