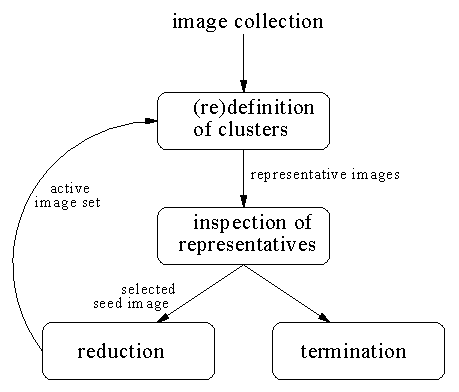
Figure 1. Filter Image Browsing retrieval process.
{vendrig, worring, smeulders}@wins.uva.nl, Intelligent Sensory Information Systems, Faculty of WINS, University of Amsterdam, Kruislaan 403, 1098 SJ Amsterdam.
Considering the disadvantages of manual indexing it is obvious that the assignment of keywords and descriptions should be automated. For full text documents elaborate indexing techniques are available, reducing large chunks of text to a short list of relevant words. Extracting textual descriptions from images is however less successful. The translation from an image object to keywords requires a great deal of knowledge about the domain. Furthermore, unlike words in a text, objects in an image cant be distinguished easily.
The problem of descriptions generation holds as well for Query by Association, the information retrieval method in which user input is a choice of one of the navigation controls, e.g. multimedia hypertext. Since the controls have to be based on the image content, the user-friendly approach of Query by Association faces the same disadvantages as keyword queries.
Context can be useful to reduce a multimedia retrieval problem to a full text retrieval problem. In [10] the Piction system is described that identifies human faces in newspaper photographs using visual semantics and natural language processing. Piction associates terms in the caption of an image with a photograph, or even a part of the photograph. The indexing is performed fully automatically. The retrieval of the images is based purely on descriptions.
Since context is not always available and indexing based on information encoded in the image itself would be less speculative, multimedia research focuses on indexing on image features. Image features are non-information-bearing [3] metadata derived directly from the pictorial data. Query by Pictorial Example is currently the most frequently used method to retrieve images, e.g. in [4], [5], [7].
In the next section the Query by Pictorial Example method will be explained in detail. Next, it is shown how disadvantages of the method can be avoided when combined with concepts from Query by Association. The resulting method is called Filter Image Browsing. Results of an experiment with a Filter Image Browsing implementation will be described, followed by conclusions and suggestions for general application of Filter Browsing in multimedia information retrieval.
Although the query formulation and the features for computing the similarity differ considerably, Query
by Pictorial Example uses the same principle as full-text information retrieval
to satisfy a user's information need. In Query by Pictorial Example, the system's purpose has changed from giving
deterministic answers to minimizing the user's search and evaluation efforts.
In QPE a user can for example provide the
image retrieval system with a picture of a red car, asking for all pictures
that appear similar. The system computes the values for the a priori defined features of the
example image and compares them to the values of the images in the database.
The user is then confronted with the images that are most likely to fulfill
her information need according to the choice of features and similarity ranking method used.
Apart from the selected image features and similarity ranking techniques, in QPE the example image given by users is of great importance. Based on the way the example image is fed to a system, we distinguish three types of Query by Pictorial Example:
Although Query by internal Pictorial Example allows simple user interaction, the method has two major disadvantages. First, the user has to go through the time consuming process of finding a suitable example image in the database. Secondly, although the Query by internal Pictorial Example method can be applied iteratively, the use of similarity ranking can cause false convergence. False convergence occurs when the top ranked images are around a local optimum of the similarity, viz. the wrong one. A falsely converged set of images does not yet comply with the users information need, but it is no longer useful for a new query, since the result of such a query would be identical.
Filter Image Browsing can be seen as an overview overlay on Query by internal
Pictorial Example, or as the addition of a dynamic zoom function for image databases
to Query by Association. The Filter Image Browsing system first presents
an overview of images that are considered representative for parts of the
image collection. The user selects an example image from the overview after
which a similarity ranking is performed. A large percentage (e.g.
25%) of the top ranked images form the new subset of images, which we call the
active image set in that state of the retrieval session.
Figure 1. Filter Image Browsing retrieval process.
Filter Image Browsing uses similarity ranking, while false convergence is limited by applying the overview techniques to the entire subset of images instead of just the top ranked images. In the following paragraphs, specifics of Filter Image Browsing will be described in more detail. Furthermore, some side effects of Filter Image Browsing will be discussed.
Filter Image Browsing is based on two functions, viz. overview and reduction. The overview function provides the user with a small yet representative set of images, so that she can choose a good example image. The reduction function makes a distinction between images that are likely to be desired and images that are not, based on the information (the selected example image) available.
In ImageRETRO, the overview function is implemented by dynamically defining
clusters of images, based on their feature values. Clusters are allowed to
overlap. For each cluster an image is chosen as a representative. The total set
of representative images is shown to the user.
The use of reduction and similarity ranking does influence the overview
function, since all images in the active set must be accessible by choosing
one of the images presented to the user. The dynamically defined
clusters must cover the entire set of images in the active image set.
Therefore, we introduce the cover constraint stating that every image in the active set
must be part of a cluster.
In ImageRETRO a brute force algorithm was constructed to enforce the cover
constraint.
The algorithm performs an imaginary reduction operation on the active set given
a seed image. The cluster is the result of the reduction operation. This is done
repeatedly (each time starting from the entire active set) until each image
in the active set is part of one of the clusters. The collection of seed images
forms the overview set. To speed up the algorithm, the seed images are chosen
such that clusters are likely to differ considerably from previous clusters.
For example, anticipating a reduction to 25% of the active image
set, the algorithm needs 12 clusters on average to guarantee the cover. In a
best case situation, only 4 clusters would be necessary. In our opinion
the number of images shown to the user in the overview should be limited from 20 to 30.
Since the brute force algorithm does not exceed this limit and it can be
executed fast enough to allow interactive retrieval, it is
useful to guarantee at least one search path to every image in the database.
We note two side effects of Filter Image Browsing that are caused by the variation
in active image sets during a retrieval session.
First, the use of smaller sets of images during the session results
in an increase of processing speed. IBMs QBIC already applies filtering
techniques for the purpose of speeding up computations solely [4].
Thus the system can use computationally expensive features once the size
of a reduced image set allows it.
Secondly, the system can use features that are appropriate for
the active image set. Features that are valuable to make a general distinction
between image clusters in the beginning of the retrieval session may loose
their value after the distinction has been made. E.g., the number of distinct
colors is a discriminating feature in a large set of images, but it is no longer
useful when all images in the reduced set have the same number of colors.
In addition, some features can be applied only when conditions are met. E.g.
color features may be useful only when there are no gray valued images present
in the image set.
Furthermore, the use of statistics determines the discriminatory power of each feature
in a state of the retrieval process, so that the importance of each feature is
related to the active image set.
As domain for the image database the World Wide Web was chosen, since it
is a large and diverse domain and the acquisition of images was practically
feasible.
A robot gathered 10,000 images by following hyperlinks. The robot could easily be used to
extend the number of images in the database. For every image index values
were computed for 9 simple image features, primarily based on colors. The
ImageRETRO system and the images are available via the World Wide Web.
Other retrieval systems that indexed images from the World Wide Web based
on pictorial content include PicToSeek [5] and WebSeek [9].
Criteria
Two types of evaluation criteria determine whether Filter Image
Browsing is effective or not. One type evaluates the
performance of the system stand-alone, while the other type compares
different image retrieval systems.
The stand-alone evaluation consists of two criteria. The first criterion measures the loss of relevant images after the reductions. It tests the decrease in precision relative to the reduction of the image sets.
Let Is be the active image set in state s. The precision P of image collection Is is the number of desired images that is present in Is as percentage of the total number of desired images:
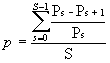
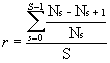
The reduction operation is considered useful, when p is significantly lower than r.
The second stand-alone criterion measures the performance of the overview functionality by comparing it to an overview function that picks images at random. The overview function is considered useful, when p/r is significantly lower in the case of the overview function than in the case of randomly picked images.
The relative evaluation compares the ImageRETRO system to a straightforward implementation
of the Query by internal Pictorial Example method. For ImageRETRO to be successful, the number
of images found after a reasonable amount of user interactions must be higher than the same
figures for Query by internal Pictorial Example. The success of a system at a stage in the
retrieval session is expressed by the recall R:
During an experiment the behavior of the user should not be random.
The purpose of the evaluation is to examine the effectiveness of the
retrieval method. Thus the serendipity of users should not be subject
to evaluation. Furthermore, the knowledge of the user should not change
during the experiment. I.e., the results of a session of finding certain
images with one method should not influence the behavior in a session of
finding the same images with an other method.
Ideally, users in the experiment search for images so that they are:
|
Reduction |
Cluster Based Overview |
Random Overview |
|
25% |
0.09 |
0.17 |
|
30% |
0.11 |
0.19 |
|
35% |
0.12 |
0.21 |
Finally, the comparison of Filter Image Browsing to a Query by internal Pictorial Example system is shown in figure 2. For each of both systems both a cluster based and a random overview were simulated. The graph shows the number of user interactions on the X axis and the cumulative recall on the Y axis. Note that cumulative recall is the number of desired images that were shown on screen to the user and that it does not concern the active set entirely. The Filter Image Browsing results are based on reductions to 35% of the active image set.
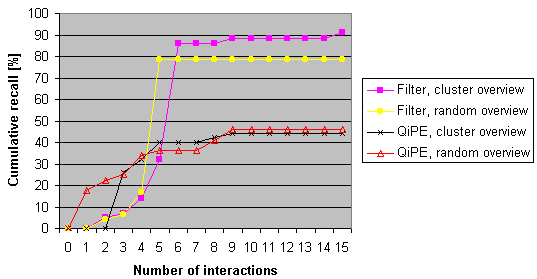
Figure 2. Comparison of Filter Image Browsing and Query by internal
Pictorial Example (QiPE).
The simulations show satisfying results for all determined criteria. Although Filter Image Browsing
does cause the loss of desired images, far more irrelevant than relevant images are discarded.
Table 1 shows that far less relevant images are lost when a cluster based overview function is used,
compared to an overview with randomly picked images.
Query by internal Pictorial Example performs the best of the two systems after only a few
actions. But after 6 interactions, which can be considered very reasonable, Filter Image
Browsing performs significantly better than Query by internal Pictorial Example. The initial investment
in interactive query specification is paid off when the set of images converges to a small set.
Thus, the combination of Query by internal Pictorial Example from the image retrieval field and
Query by Association from hypertext research in Filter Image Browsing results in a
powerful method for browsing through image databases.
In future research, we will apply a similar approach to full-text databases,
so that users can find documents by iteratively choosing automatically
indexed keywords from the database. In cooperation with Origin/Medialab
an application using such techniques is currently under development. Later,
combination of image and full-text Filter Browsing will lead to a uniform approach
for multimedia information retrieval.
In addition, we plan to extend Filter Browsing systems with innovative interfaces,
such as Medialabs Aquabrowser [11]. The combination of user-friendly
interfaces and powerful adaptive retrieval systems has to result in intuitive
access to multimedia databases.
[2] D.R. Cutting, D.R. Karger, J.O. Pedersen and J.W. Tukey. Scather/gather: A cluster-based approach to to browsing large document collections. In: Proceedings of SIGIR'92, 1992.
[3] W.I. Grosky. Multimedia Information Systems. IEEE Multimedia, 1(1):12-24, 1994.
[4] M. Flickner, H. Sawhney, W. Niblack, J. Ashley, Q. Huang, B. Dom, M. Gorkani, J. Hafner, D. Lee, D. Petkovic, D. Steele and P. Yanker. Query by Image and Video Content: The QBIC System. IEEE Computer, 28(9):23-32, 1995. (demo)
[5] T. Gevers and A.W.M. Smeulders. PicToSeek: A Content-based Image Search Engine for the World Wide Web. In Proceedings of VISUAL'97, San Diego, USA, 1997. (demo)
[6] R. Jain. Infoscopes: multimedia information systems. In Multimedia Systems and Techniques, B. Furht, ed., Kluwer Academic Publishers, Boston, 1996, pp. 217-253.
[7] A. Pentland, R.W. Picard, S. Sclaroff. Photobook: content-based manipulation of image databases. In Borko Furht, editor, Multimedia Tools and Applications, Kluwer Academic Publishers, Boston, 1996, pp. 43-80.
[8] S.W. Smoliar and H.J. Zhang. Video Indexing and Retrieval. In Multimedia Systems and Techniques, B. Furht, ed., Kluwer Academic Publishers, Boston, 1996, pp. 293-322.
[9] J. R. Smith and S.-F. Chang. Visually Searching the Web for Content. IEEE Multimedia, 4(3):12-20, 1997. (demo)
[10] R.K. Srihari. Automatic Indexing and Content-Based Retrieval of Captioned Images. IEEE Computer, 28(9):49-56, 1995.
[11] W.A. Veling. The Aqua Browser - visualisation of dynamic concept spaces. Digital Intelligence (AGSI 97), The Hague, The Netherlands, accepted for publication. (demo)
[12] J. Vendrig. Filter Image Browsing: a study to image retrieval in large pictorial databases. Msc Thesis, University of Amsterdam, The Netherlands, February 1997. (demo)
Authors
More information about the authors and their current research interests can be found at their homepages.