|
Peter Funk
|
Owen Conlan |
Educational Adaptive Hypermedia Systems (AHS) are capable of producing personalized learning courses that are tailored to various learning preferences and characteristics of the learner. In the past AHS traditionally have embedded experts’ knowledge in the structure of AHS content and applied appropriate design models. However, such systems have continually been criticized for believing that this is sufficient for effective learning to occur [11]. For a tutor who develops such a system there may be many permutations of narrative, concepts and content that may be combined to produce the tailored learner courses. However, the more levels of personalization the system can provide the greater likelihood exists that the system may produce an unforeseen or undesired effect. As a tutor it can be difficult to monitor the suitability of the personalized course offerings on an individual learner basis. Addressed in this paper are these questions: How can feedback about the effectiveness of highly personalized courses offerings be gathered and returned to the author? and Can CBR techniques be utilized to identify suitable candidate content for narrative population? By utilizing CBR techniques as a form of quality assurance for the author fine-grained stereotypes, in content or learner models, may be identified. This paper provides a high level overview of a technique for predicting/monitoring personalized course suitability and increasing the quality of delivered courses using CBR in combination with other techniques, e.g. filtering techniques.
Research in knowledge management deals with methods, models and strategies to capture, reuse and maintain knowledge. Knowledge management, and in particular experience management which focuses on previous stored experience, e.g. previous learners performance and feedback in context of a specific course, is highly relevant for AHSs especially later developments where different methods and techniques from artificial intelligence are included, such as case-based reasoning, clustering and filtering techniques [4]. We will focus on two main issues:
The paper explores how AHSs may benefit from case-based reasoning and filtering techniques and some of the challenges these systems offer case-based reasoning researchers.
In adaptive education systems an experience management approach may be used to deliver personalized courses based on the both current learner performance and on the performance of learners, together with the experiences of using different narratives and content models. Using filtering techniques (filtering suggestions/adaptations through the preferences/results of other similar learners) enables the system to reuse experience from similar learners’ preferences, successes and failures to improve adaptation to current users’ needs and preferences. These approaches, however, traditionally suffer from a training period before the system can produce accurate recommendations.
Techniques such as category based filtering [10] may be used if learner models, content (material with the purpose to transfer specific knowledge to the learner, may have the form of text documents, animation, simulation, contain interaction, tasks, etc.), narratives and results from different individual learners are fragmented (e.g. different learners have completed different content but not a full course) and sparse. Compared with other filtering techniques category based filtering requires categorization of all items and clusters users/learners into learner stereotypes which reduce the latency problem, e.g. if previously a learner has not been able to review and give feedback on a complete course and their constituent content components, category based filtering is able to reduce this problem and give recommendations based on learner stereotypes instead of individual learners.
In rule based expert systems there are no latency problems as the personalized course is generated based on rules developed by an expert in the knowledge domain [2]. The more complexity that is built into such rules the more likely it is that the system will produce a course that does not fully cater to the learner's needs, deviating from the author’s original goals. Managing large sets of rules also requires much effort from the expert (the tutors in an AH system).
The suitability of a personalized course offering can be determined by examining the learner's feedback, explicit and implicit [8]. The feedback may be given by, or requested from the user, or gathered implicitly by analysis and evaluation of the learner’s progress and results. As a tutor, however, it can be difficult to spot the trends in this feedback and correlating it with the personalized courses generated.
A case-based reasoning approach is proposed for identifying and correcting potential problems with personalized courses by matching, reusing, validating and storing cases, where cases may be individual learner models, narratives or individual content models. Producing learner stereotypes using clustering techniques, and comparing the stereotypes can overcome the latency problem. This paper outlines this approach in the context of an existing research Adaptive Hypermedia Service, APeLS (Adaptive Personalized eLearning Service) system developed at Trinity College, Dublin [3].
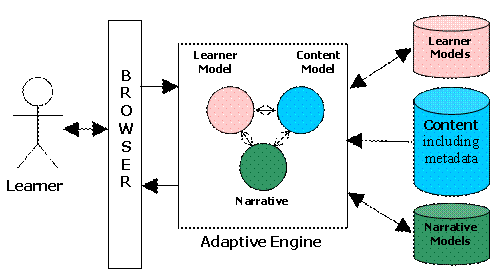
Multi-model Adaptive Hypermedia Services combine information models about learners, learning content and narrative structures, i.e. what knowledge to transfer to this particular learner to produce personalized course offerings to learners. This enables the Adaptive Hypermedia Service to deliver personalized eLearning courses. These three components are characterized as distinct, and separate, models within the Adaptive Hypermedia Service (see Figure 1).
The learner model contains a model of the learner with respect to learning preferences, knowledge, preferred learning style, results etc. The content model represents the learning content which may be selected to be taught to a particular learner. The learning content may be rendered in a variety of ways , e.g. text documents, slides, animation, simulation, interactive, etc. [3] proposes a mechanism that enables the personalized course structures to be described in terms of concepts rather than the pieces of learning content that teach those concepts. This abstraction enables the Adaptive Hypermedia Service to populate the concept with an appropriate piece of learning content at runtime. For example, if the learner prefers interactive content then a kinesthetic piece of content may be delivered over a non-interactive visual piece of content. The domain or narrative model is responsible for describing the possible combinations of learning concepts that may be assembled to fulfill a learner’s personal learning goals.
Fig. 1. Multi-model Adaptive Hypermedia Service
This approach has at least two potential problem areas that the domain expert who designs the narrative (in the form of rules/examples on how to combine, select and order material for different learners and their preferences) may not be able to foresee –
As the narrative models become more complex (or begin incorporating other narrative models) the task of foreseeing and/or diagnosing these problems in the personalized course becomes increasingly difficult for the domain expert. This task is further complicated by the ability to associate multiple base narratives with one course – each narrative produces personalized courses with the concepts sequenced in different ways catering to the learning styles of different learners.
In these situations it would be desirable to correlate learner feedback (performance on tests, explicit querying, learners’ behavior during learning etc.) with the personalized course offerings to determine trends and identify potential problems. The feedback given may be classified to the following categories:
The feedback is elicited in a number of different ways and may also need some analysis to enable conclusions. The feedback may not be deterministic, merely strengthening or weakening beliefs. Some feedback may be used to dynamically revise the personalization of the course; other feedback is used to improve the quality of future personalization for learners, in particular for similar learners. This approach fits well with the concept of case-based reasoning and collaborative filtering with minor modifications, outlined in following section 3 and 4.
A number of different parts in the adaptive hypermedia system can be used in a case-based reasoning approach to develop AHSs, reuse and personalization. The filtering approach is used to recommend and select items, inside our outside a case based reasoning cycle, using experience from other learners, authors and tutors.
During the process when authors design courses, a CBR approach may be used where content, concept, narrative may be reused from similar courses designed by other authors. Since the components in the AHS are standards-based [3] learning content repositories, on the web, may be used and during the authors work, the design tools may invoke a CBR system to identify and propose similar cases. Once found, the CBR system may perform some adaptation to adapt or combine the material with the authors design. Final revision is performed by the author and the case is stored in the case library, ready to be used by the personalization learning service. By combining this technique with the abstraction architecture [3] the CBR system may be used to populate concepts with appropriate content.
Learning content and concepts have a high potential for reuse. Using feedback on how successful they are in different situations their appropriateness for reuse in different circumstances may be determined. Content may also be reused in the CBR cycle for automatic personalization during learning sessions, and may even identify content not initially thought of by the tutor (the learner/tutor should be informed if this is the case). The advantage is that it is a closed cycle and able to handle both feedback, direct in the form of learners comments and indirect by comparing the learners result with the result of other cases. Feedback from tutor observation is also handled and of value when revising a course or designing a similar course.
Filtering techniques are proposed where the main task is to identify the learner’s preferences and needs based on previous learners’ results, behavior and feedback. Category based filtering is especially suitable if all objects are categorized in advance, which is the case in the personalized learning service (the author may create additional metadata and classifications during narrative design). In the next section we will outline the proposal in more detail.
Category based filtering as described in [10] is based on category ratings. In the personalized learning service the content is categorized by concepts. A category bases filtering system is able to use the concepts as categories. To reduce the latency problem, content models and their specific narratives are clustered in clusters of similar users (a number of different approaches to perform clustering exist). Learners may be part of more than one cluster. These clusters are then merged to a stereotype learner for this cluster and will be more complete than individual learners. A new user can often be classified to belong to one of these categories, and the category can be used to guide the personalization until enough is known about the user to pass the personalization entirely on the users user model. In Figure 2 an example on how category based filtering can be used to recommend similar learner models to use in the personalization process. Clustering is used to generate a number of learner stereotypes, useful if learner models are sparse and incomplete (few learners may have completed a similar course, just covered it in part). The dotted line from learner models indicates that learner stereotypes are preferred and learner models only used if there is a good mach and no good mach amongst stereotypes (stereotypes capture experience from a larger group of similar learners).
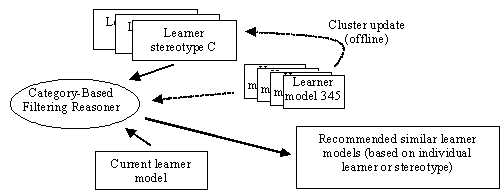
Fig. 2. Outline of an adaptation of category
based filtering,
as described in [10].
A learner model may also include references to previously learned courses, their content models, content, narratives, feedback and results (used in the personalization process).
As discussed in the previous section there are a number of tasks and problems that can be addressed with case-based reasoning and filtering techniques. In this section we will describe the APeLS system in terms of cases and explore how case-based reasoning may be applied in AHS systems, both aiding the experts to improve and refine eLearning courses and also improve online personalization by using feedback on learning objects and concepts to make modifications in content model and selected learning objects (content). In section 2 we discussed the problems for a domain expert to be able to see all implications on how a course can be personalized from the set of narrative rules and how well a selected learning object for a concept meets all learners’ personalization requirements.
Each concept, added by the execution of a narrative, requires some prior competences from the learner and results in additional learned competences after successful completion. Each concept is, after personalization, populated by a candidate selector (CS) and the learning style of the learner should be considered in selecting the candidate. The socket on the lower left side of the CS is an illustration of the learning style, i.e. a learning concept is not completely seen as a black box. The learning style or pedagogical approach of the successful candidate should engage the learner. Candidates may also be used to cater for technical limitations of the delivery device (learner working from different locations may have bandwidth limitations on some occasions, e.g. not able to view video examples).

Fig. 3. Structure of a candidate selector
Candidate selection may also be used at the course level. In order to meet all on the learning goals of the course, the course has do be comprised from a number of concepts and corresponding Candidate Selectors. The CSs should match the learner’s preferred learning style and sequence, combination, granularity and order should follow the narrative rules. Constructing a course could be viewed as a planning task where requirements and restrictions are enforced by the narrative and competencies required and learned.
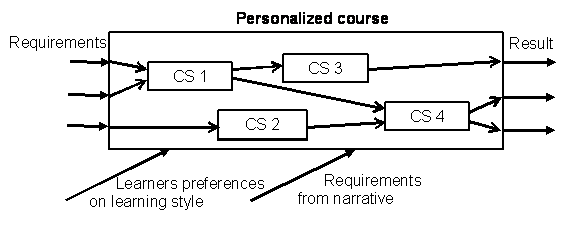
Fig. 4. Example of a personalized course with candidate selectors
Ordering is determined by the narrative, where experts have created rules and each learning object may have prerequisite requirements (knowledge or competencies the learner is supposed to have) and outcomes (knowledge the learner has acquired after successful completion of the learning object). The full search space may be very large since different parts of the multiple models may be used as input information along with feedback from the learner. CBR systems are able to handle models and processes and are both able to correct problems and reuse parts of models and models in full, see e.g. [6].
Describing the APeLS system in terms of cases, both case selectors, concepts and courses are seen as cases, giving a number of interesting opportunities for case-based reasoning researchers and valuable benefits to the AH system. Cases can be reused in part and in full. Looking at the system in this CBR view also reveals the usefulness of separating the narrative from the learning content [3]. The narrative can be used both in validation of content, case selectors and courses, and also be used as adaptation rules during the reuse phase, see Figure 5.
Concepts, candidate selectors and content can now be used in a CBR system and aid the tutor/author in adapting an existing course or in designing a new course. There are a number of exciting challenges for case-based reasoning researchers as many of the tasks in AHSs are complex. How to populate concepts with content is, for a tutor, a difficult task, and using content containing learner feedback in a case-based approach is interesting to explore (candidate selector using CBR). An interesting issue is the interactive nature and relationship between the different parts of the AHS, and an interesting approach is to work on more than one case-library at the same time. Other avenues include combining CBR with category based filtering systems to recommend appropriate candidates/examples that are used in the adaptation and validation process.
Also ensuring the quality for a new course or after adapting a course is a relevant issue and the challenge in how to use the feedback in cases; it may even be relevant to look for similar cases which previously have shown to be unsuitable. These cases can be used in the adaptation and validation process to ensure the author/tutor does not produce a course that repeats mistakes previously made (e.g. if experience has shown that a particular configuration leads to more failures amongst learners). This may also be valuable when performing on line adaptation - if the learner changes his/her preferences and is proposed a personalized course with corresponding features, the system may recognize from other learners with similar preferences and courses that the learning result takes longer time or learners score lower and even suggest alternatives (e.g. some engineering students selecting personalization with examples may score higher than engineering students selecting abstract theoretical learning content).
In this paper we outlined how an existing research Adaptive Hypermedia Service [3] may benefit from CBR and filtering techniques in a number of different ways, in particular how author/tutor may be aided in designing and adapting courses. An important issue is feedback collected in the cases and used both in the adaptation process and the validation process to insure quality and efficiency. Using category based filtering and clustering learner models to find similar learner models used in the personalization process is one example such benefits. Another example discussed is how CBR may be used to populate concept groups with learning content, potentially using the case library. Using less successful examples in the CBR adaptation and validation process to avoid repeating solutions shown to be less successful is proposed. Also the fact that the adaptation may be improved by comparing the current user model with other similar users involved in a similar course is interesting, and a challenge would be to construct a CBR system uses multiple case libraries.
The plans for the future are to select a number of the ideas and challenges outlined in this paper for improving the effectiveness of adaptive features of AHS, and implement them in a collaborative project between Trinity College, Dublin and Mälardalen University, Västerås. It is hoped that this approach will yield greater and more focused feedback to the author/tutors of adaptive courses enabling them to improve the learning experience for the learner. Also the reuse of components in AHS systems will be further aided by this approach and it is hoped that such an approach will result in shared repositories of components between different universities worldwide enabling tutors to design efficient and high quality personalized courses for their students.
The proposed implementation will combine the adaptive AHS system, APeLS, developed by Trinity College, Dublin [3] with the category-based filtering approach and CBR system developed at Mälardalen University, Västerås [6], [10] to produce a system that uses the information gathered about learners partaking in personalized courses to produce recommendations to the course author as to how the adaptive features may be better tuned and aid reuse.