Figure 1 - Functional architecture of SiteIF (full-size)
Abstract: The growing size and complexity of WWW made evident the need to provide more flexible mechanisms for delivering personalized information to the user. On the other side, knowledge of customers interests could be a real advantage for companies that work using Internet and want to develop personalized marketing applications. This paper gives an overview of the SiteIF system. SiteIF takes into account the user's browsing behavior and tries to anticipate what documents in the web site could be interesting for the user. The system dynamically learns the user's areas of interest generating/updating a user model. The architecture of the system consists of many components. The paper focuses on the agents that model the user interest and generate personal documents as entry points in the site.
Keywords: Internet, Information Filtering, User Modeling, Intelligent Agents, Personalized Marketing.
In the last years we have seen a continued growing of the information available on Internet. The expansion of this net, of the local nets and of the documents and resources contained by them, has been stressed sometimes with enthusiastic words, sometimes in alarmist ways, by many authors that tried to quantify its dimensions. In the analysis described in [Bray, 1996], written in the November 1995, more than eleven millions of documents have been found. In [Etzioni & Weld, 1995] the authors wrote that in the May 1995, every day more than 30 millions of people used Internet, and every person is a potential producer of information.
More information becomes available, more difficulties have the users to control and effectively manage the potentially endless flow of information: it is not easy to find what you are looking for unless you know exactly where to get it from and how to do it.
Information filtering systems can help users eliminate useless documents and bring to their attention only the relevant information. This implies that the system has to be able to recognize the users and to maintain a model for their interests.
Several tools have been proposed in literature to search and retrieve relevant documents ([Lieberman, 1995]; [Armstrong et al., 1995]; [Kamba & Sakagami, 1997]; [Minio & Tasso, 1996]). Anyway all these systems share two basic limitations: the technique used to represent a user's profile is based on simple lists of keywords (and single words are often not enough to describe someone's interests) and the learning method requires the users' conscious and active involvement filling a form of keywords (topics) for their interests or adding a score to each visited document.
This paper describes SiteIF system. SiteIF acts as a housekeeper for a web site. It works with an ordinary web browser that supports Java, tracks down the user's browsing behavior (e.g. following links) and tries to anticipate what documents in the site could be interesting for the user.
From a marketing point of view, knowledge of customers' profiles is a resource to reach a good one-to-one relation, allowing the development of personalized applications following the needs of every user.
Section 2 gives an overview of SiteIF functionality and structure. Examples of the user interaction with SiteIF system are presented in section 3. Section 4 presents some directions for a further development.
SiteIF is a personal agent that follows the users from page to page as they browse the web site, "watching over the user's shoulder". It learns user's interests from the requested pages that are analysed to generate or update a model of the user.
This model is represented using a semantic net developed similarly to IFTool system [Minio & Tasso, 1996]. However, unlike from IFTool, SiteIF avoids involving the user in its learning process (it does not ask the user for any keywords or opinions about pages) and only takes into account the addresses of the visited pages.
In this way it is possible to give advices about pages and documents of the web site that SiteIF supposes could be interesting for the user. The whole system is implemented in approximately 3100 lines of Java code and 290 lines of C code.
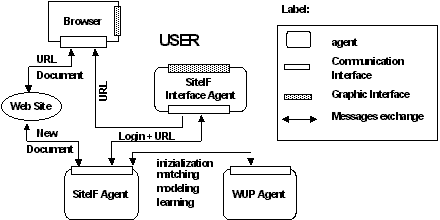
Figure 1 shows the SiteIF architecture which includes the following modules:
Figure 1 - Functional architecture of SiteIF (full-size)
User can interact through two graphic interfaces: the first is controlled by the SiteIF Interface Agent, the second is the browser itself. The SiteIF Agent is called by the SiteIF Interface Agent that sends a request of identification/authentication and, once verified, it allows the user to enter the web site. The SiteIF Interface Agent follows and monitors the actions of the user inside the site. Every time he/she follows a link, the selected URL is sent to the SiteIF Agent while the Netscape window displays the requested document. The SiteIF Agent records all the browsed documents in a log file.
The log file is sent to the WUP Agent that initializes or updates the user model. After the modelling phase, the WUP agent filters the documents of the site according to the user model built before and sends back the results to the SiteIF Agent.
Now we briefly describe features and functionalities of the implemented agents. Every agent has a quite complex architecture that can be divided in other sub-agents or modules.
In Figure 2 it is shown the functional architecture of SiteIF Agent. This agent manages different functions: it logs the pages visited by the user (in a log file that will be sent to the WUP Agent) and creates "on the fly" personal documents based on user's interests. For the moment these personal documents are simple lists of results. A natural language generation module, that creates personalized HTML pages, is under development.
SiteIF Agent is made up of the following elements:
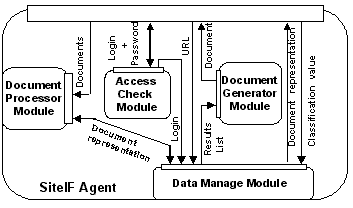
Figure 2 - Functional architecture of SiteIF Agent (full-size)
The WUP (Web User Profiling) Agent implements the following steps: the user modelling, the comparison of the internal representation of the document with the user model and, on the basis of the obtained results, the classification of the document (i.e. interesting or not interesting).
The WUP Agent yields the user model as a semantic net. Every node is a word (or an interesting concept) and the arcs between nodes are the co-occurrence relation of two words; every node and every arc has a weight (that represents a different level of interest for the user).
The weights are periodically reconsidered and possibly lowered (depending on the time passed from the last update). Also no more useful nodes and arcs may be removed from the net. So it is possible to consider changes of the user's interests and to avoid that uninteresting concepts remain in the user model.
During the filtering phase, the matching module receives as input the internal representation of a document and the current user model. It produces as output a classification of the document (i.e. it is worth or not the user's attention).
In literature ([Stevens, 1992], [Hoeffer et al., 1995], [Baclace, 1992]) the most used matching technique is the standard keyword matching: a simple count of the terms which are simultaneously present in the document representation and in the user model. This technique has some problems for the synonymy and plural meanings of some words [Foltz & Dumais, 1992]. A lot of words describe different concepts if used in different contents. For example the words "system", "expert" and "operative": the first and the second word can occur in a document about expert systems, while the first and the third can be found in operative system pages. So the "system" word can have more than one meanings, depending on the context in which it is used.
The idea behind SiteIF algorithm consists of checking, for every word in the representation of the document, whether the context in which it occurs has been already found in previously visited documents and already stored in the semantic net. This context is represented by the co-occurrence relationship, that is by the couples of terms included in the document which have already co-occurred before in other documents (information represented by arcs of the semantic net).
In this section, we present a sample session, run with a user model partially filled in previous sessions. The user types his access codes in the fields LOGIN and PASSWORD and clicks on the CONNECT button (Figure 3).
Figure 3 - WWW page to access the SiteIF System. (full-size)
Then, the SiteIF System Interface (Figure 4), a document generated on the fly by the SiteIF Interface Agent, is displayed to the user. It contains a range of all the possible documents that the system "thinks" could be useful or interesting for the user (the list box on the left, contains all the classes in which the site having at least an interesting document; the list box on the right shows the documents of the class selected in the left list, ordered by a decreasing way following the value of interest).
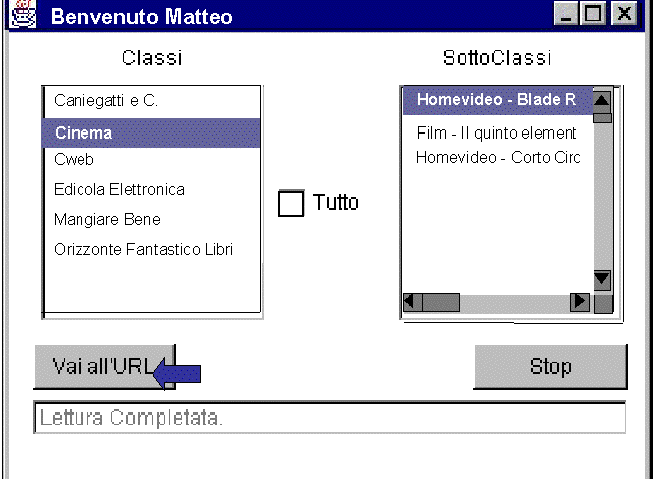
Figure 4 - User interface of SiteIF(full-size)
Every time a user clicks on a link of the list, the applet takes into account the URL and opens that URL it in the Netscape window (Figure 5).
Figure 5 - Document related to the URL chosen by the user, shown in the Netscape window.(full-size)
If the user is not interested in the suggested documents, he can select the control box TUTTO and go on with the normal browsing of the site. Even in this way, the applet records and logs all the choices of the user and the URLs of the followed links.
In this paper we have described the SiteIF system. SiteIF takes into account the user's browsing behavior and tries to anticipate what documents in the web site could be interesting for the user. The system interactively and incrementally learns about the user's areas of interest generating/updating a user's model.
This paper describes a work in progress. At this point we don't have final evaluations of the effectiveness of the system, although preliminary tests are encouraging. A complete evaluation test is planned in collaboration with Telecom Italia Network, one of the more important Italian service provider.
There are many possible future developments:
Using systems such as SiteIF will be fundamental for companies that work using Internet and that want to develop personalized marketing applications following the needs of every customer. At the moment not all the companies have customers that use Internet, but it is only a matter of time. If the activity will grow at an international level, this is certainly the way to follow. Who starts today will be in a better position tomorrow, when Internet and WWW will become tools for everybody.
[Asnicar & Tasso, 1997] Asnicar, F.; Tasso, C. ifWeb: a Prototype of user models based intelligent agent for document filtering and navigation in the world wide web, Sixth International Conference on User Modeling, Chia Laguna, Sardinia, Italy, 2-5 June 1997. Rif.: http://www.dimi.uniud.it/~ift/positionp.html
[Baclace, 1992] Baclace, M.C. Competitive agents for information filtering, Communications of the ACM, 35(12), pp. 50, 1992.
[Bray, 1996] Bray, T. Measuring the Web , Proceedings of the Fifth International World Wide Web Conference, Paris, France, May 1996, in Computer Networks and ISDN Systems 28(7-11), pp. 993-1005, 1996.
[Etzioni & Weld, 1995] Etzioni , O.; Weld, D. S. Intelligent Agents on the Internet: Fact, Fiction, and Forecast, in IEEE Expert, August 1995.
[Foltz & Dumais, 1992] Foltz, P.W.; Dumais, S.T. Personalized information delivery: an analysis of information filtering methods, in Communication of the ACM, 35(12), pp. 51-60, 1992.
[Hoeffer et al., 1995] Hoeffer, M.; Knaus, B.; Winiwarter, W. An Evolutionary Approach to Cognitive Information Filtering, SIGIR95, 1995.
[Kamba & Sakagami, 1997] Kamba, T.; Sakagami, H. Learning Personal Preferences on online Newspaper articles from user behaviors, Sixth International World Wide Web Conference Proceedings, 1997. Rif.: http://proceedings.www6conf.org
[Lieberman, 1995] Lieberman, H. Letizia: An Agent that assists Web browsing. Proceedings of the 1995 International Joint Conference on Artificial Intelligent, Montreal, Canada, August 1995. Rif.: http://agents.www.media.mit.edu/groups/agents/papers/
[Minio & Tasso, 1996] Minio, M.; Tasso, C. User Modeling for Information Filtering on INTERNET Services: Exploiting an Extended Version of the UMT Shell, Workshop on User Modeling for Information Filtering on the World Wide Web, in Proceedings of the Fifth International Conference on User Modeling, Kailia-Kuna Hawaii, January 1996. Rif.: http://www.cs.ju.oz.au/bob/um96-workshop.html
[Salton & McGill, 1983] Salton, G.; McGill, M.H. Introduction to modern information retrieval, McGraw-Hill, New York, 1983.
[Stevens, 1992] Stevens, C. Automating the creation of
information filters, in Communications of the ACM,
35(12), p. 48, 1992.
Most part of the work was made when the first author was at University of Trento, Economics Department, during her degree thesis.