Proceedings of the 2nd Workshop on Adaptive Systems and User Modeling on the WWW
Nicola Henze
and Wolfgang Nejdl
Knowledge Based Systems Group
University of Hannover, Lange Laube 3, 30159 Hannover, Germany
Phone: +49 511 762 9711, Fax: +49 511 762 9712
e-mail: {henze | nejdl}@kbs.uni-hannover.de
Abstract: We have implemented an adaptive hyperbook system (KBS Hyperbook) for an introductory course on computer science (CS1). The adaptation techniques used for this course are based on a goal-driven approach. This allows students to choose their own learning goals and to get suggestions for suitable projects and information units covering the knowledge required to reach these learning goals. In addition, sequential paths through the hyperbook are generated which provide the student with required knowledge. The student modeling component underlying our hyperbook system uses a model of the application domain which contains knowledge items (KI) covered by the particular hyperbook and learning dependencies between these KIs. For calculating the system's belief of a user's knowledge on each KI we use a Bayesian network. We propose a project selection algorithm based on user goals and previous knowledge, and a constructive trail mechanism that generates guided tours through the hyperbook containing all prerequisites needed by a particular user to perform a specific project.
Keywords: Educational Hypermedia, Adaptive Hypermedia on the WWW
One of the main goals of student modeling in educational hypermedia is student guidance [2]. Students have learning goals and previous knowledge which should be reflected by the hyperbook for adapting the content or the link structure of the hyper document. For our KBS hyperbook system we follow a constructivistic pedagogic approach, building on project based learning, group work and discussions [10]. Such a project-based learning environment leads to new requirements for adaptation, in order to adapt the project resources presented in a set of hypermedia documents to the student's goals for a specific project and the student's knowledge. It has to support the student learner by implementing the following adaptation functionality:
In this paper we will describe the implementation of these adaptation requirements within our hyperbooks.
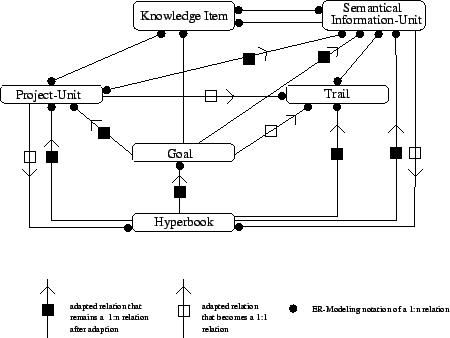
Figure 1 shows part of the high level structure of our hyperbook, and, simultaneously, the different learning strategies in our environment, and the resulting link adaptation tasks. The notation we use in this figure is a kind of ER-modeling notation which shows concepts as boxes, relations (1:1, 1:n, m:n) as links, and two kinds of adapted relations. The main content of the hyperbook consists of semantic information units and project units. Both of these refer to the actual content to be displayed on the WWW as pages of the hyperbook (see [8,9] for a description of the basic principles and the implementation of the KBS hyperbook system).
|
|
All implemented adaption strategies in our hyperbook are based on knowledge items. Such a knowledge item ( ) denotes a knowledge concept of the application domain. These concepts could be elementary, for example the "if"- or "while"-concepts in a programming language, or compound, like "knowledge about flow control statements". All s are connected in a single dependency graph as described in section 1.1.3. The knowledge items are used for indexing the contents of information units, project units and for describing the range of goals. They are similar to the domain model concepts used in [3].
Information units do not correspond to syntactical parts of a book (such as sections or chapters), but semantical parts (such as information units about "java objects", "iteration constructs", "parameters", etc.). They are semantically related to other information units (i.e. "object" and "object instantiation" are related information units). These semantic relationships generate the navigational structure between the information units (which is done dynamically by the KBS hyperbook system), so each link between information units corresponds to some kind of semantic relationship between these units. For discussion of these semantic relationships we refer to [15]. This navigational structure can be annotated as "already known", "suggested", "too difficult", according to the current knowledge of the reader ( adaptive navigational structure). For this annotation, we use the well known traffic light metaphor (see e.g. [3,19]).
Information units are indexed by knowledge items. As information units are already semantic entities, in many cases we have a one to one correspondence between information units and knowledge items. One or more of the knowledge items belonging to a page are the main knowledge items, and for each knowledge item there is exactly one information unit, where it is a main knowledge item (see figure 2).
|
|
So we have something like a knowledge item index, which gives for each knowledge item one main information unit, and some other information units where it occurs, too, but not as main knowledge item.
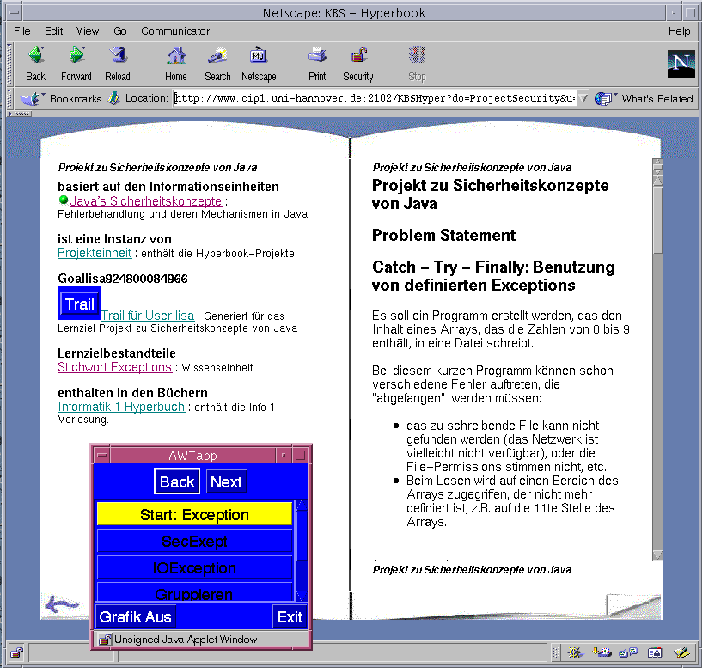
Project units contain project description, e.g. excercises or examples of solved problems. We call them projects because we want to emphasize that these excercises are designed like real-world problems (see constructivist learning theory), embedded in a complex context. Consider for example the project "security concepts in Java". Here the task for the students is to write a secure Java programm which saves some data in a file on the network. The situation in which this programm should work is described, as well as some hints: What should happen if the network is not reachable? What to do if the permissions of the file are not correct? etc. To support the student's work on the project the system has to compute relevant semantic information units.
The project units are indexed by those knowledge items which the student needs to know in order to work successfully on these projects. The relationship between project units and information units can be derived automatically via the knowledge items and shows the information units which are relevant for a given project. The links corresponding to this relationship can be adapted as well. This is done by annotating the links according to the user's knowledge ("already known", "suggested", "too difficult"), leading to an adaptive information resource for a given project. The annotated links are shown as an annotated index (from the project unit to the corresponding information units). The above mentioned project "security concepts in Java" can be successfully solved by using different solution strategies: E.g. the student could use Java's predefined exceptions or user-defined exceptions, the exceptions can be grouped for effective error handling, etc. Thus this project should be indexed by the s about error handling, grouping of exception, etc. Since the s are connected in a dependecy graph it is sufficient to index this project with only one , which aggregates knowledge about exception handling in Java.
The system can also generate a sequential trail (guided tour) through these information units relevant for a project, leaving out already known information units, and ordering the remaining information units, such that difficult information units are suggested at a later stage, when the user knows enough in order to understand them ( adaptive trail generation). For the project "security concepts in Java", the generated trail is the sequence of the semantic information units "exception in Java", "What are security exceptions?", "input / output exceptions", "grouping of exceptions", "handling exceptions" and "exception hierarchy". The example project and the trail can be seen in figure 3.|
|
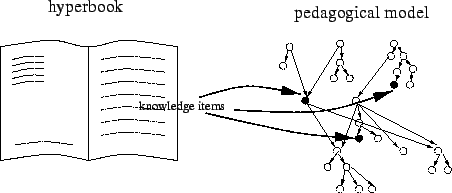
The student modeling component used in the KBS hyperbook system is based on a pedagogical model of the domain of a hyperbook. This pedagogical model contains the knowledge items mentioned in the previous section and adds a partial order between these s to represent learning dependencies, where KI1 < KI2 denotes the fact that KI1 has to be learned before KI2, because understanding KI1 is a prerequisite for understanding KI2.
The student model also contains descriptions of each user's current knowledge in the form of a -vector. This -vector contains for every the system's estimation about a particular student's knowledge. Observations about the student's work with the hyperbook are stored in terms of a : Each observation expresses the grade of knowledge the user has on a . We use four grades: A student can have "expert's knowledge" on a , "advanced knowledge", "beginner's knowledge" or "newcomer's knowledge". Since we represent the user's knowledge on a as a probability distribution, finer grades are possible as well.
The separation of hyperbook model and pedagogical model has advantages for authoring the hyperbook, as learning dependencies between knowledge items are described once in the pedagogical model, and the dependencies between information units of the hyperbook can be inferred automatically from the -dependencies and the indexing of the information units by the s. The implementation technique used in our student model component is a Bayesian network1. This BN contains the knowledge items as network nodes. The dependencies between s are expressed by conditional probabilities between the s (a detailed description can be found in a technical report [11]). The observations about a user encoded in the grades of knowledge the user has about a are directly used as input for the BN. BNs are very useful for our student modeling approach, since they allow to describe the application domain in a single dependency graph which contains all necessary prerequisites for a particular knowledge item and models dependencies among knowledge items. By using a Bayesian network we are able to infer, for example, that a user mastering an advanced topic has also knowledge about the required prerequisites of this topic.
There are several systems which use the fact, that the user "reads" some information, to update the estimate of the user's knowledge (e.g. [3]), and also include reading time and/or the sequence of read pages to enhance this estimation. While this is a viable approach, it has the disadvantage, that it is difficult to measure the knowledge a user gains who "reads" a HTML-page [2]. In the current state of our development, we decided neither to take information about visited pages into account nor the user's path through the hypertext. Instead we use only the projects for updating the system. Either we ask the student for direct feedback after working on a project: The student judges her/his performance in the categories "topic was easy - I mastered it effortless", "topic was okay - but some problems were arising", "topic was hard - I had a few ideas but could not get the thing right" and "no idea about this topic at all". Or we ask some experts to judge the student's project performance and use this judgement as observations about the student's work.
Often a user needs information about specific topics but lacks prerequisite knowledge for these topics (e.g. a user wants to work on a project about "algorithms" but does not understand "simple control structures" or "methods"). In such circumstances it does not help to start reading the information unit about "algorithms". To support the user in this situation, we compare the user's actual knowledge with the required knowledge needed to understand the requested topic. If the user lacks some requirements we generate a sequence of information units (trail or guided tour) that guides his learning towards the selected topic.
Generating such a trail is implemented by a depth-first-traversal algorithm which checks the system's estimate of the user's knowledge of those s that are prerequisites for the actual goal. The algorithm checks if all prerequisite knowledge is sufficiently known by the user; if not, the corresponding information units of the hyperbook are marked. Afterwards a sequence of all those marked units is generated which leads from the simple to the complicated topics unto the selected topic. Furthermore, the hyperbook provides direct access to information resources needed for the actual task (information goal or project). This information resource is generated by the same depth-first-traversal algorithm as mentioned above but contains all found informations units. It is displayed as a sorted index, each link annotated according to the user's knowledge by using the traffic light metaphor.
In order to select suitable projects for a user the hyperbook contains a project library. Each project is indexed by the s that have to be understood in order to successfully complete the project. These s are weighted due to their relevance for the project. As we use a Bayesian network for modeling the user's knowledge, we do not have to include prerequisite knowledge items, because they are already taken care of by the dependency structure modelled in the BN. For example, the project "security concepts in Java" mentioned above is indexed by the "exception handling" with a relevance of 100%; a project "thinking about cars" which is an introduction to the ideas of objects, is indexed by the s "classes in object-orientation" (30%), "objects" (20%), "messages" (20%), and "inheritance" (30%). The fact that the relevancies sum up to 100% is only a matter of computation. We plan to provide forms for the authors of projects where they could determine the relevance of a for a project by using sliders.
A project is useful for a user in his current knowledge state and his situation, if
These requirements determine the selection criteria for finding an appropriate project for a user that helps the user to achieve his or her learning goal and reflects his or her current knowledge state. They are implemented by two algorithms. The first one calculates how good a project matches the goal of a user ( project-goal-distance). The second one determines whether the actual knowledge of a user is sufficient for performing the suggested project without too many difficulties ( fitness). For example, a student who is interested in learning simple control structures in Java will have difficulties with a project that uses control structures to build a graphical user interface if she/he has only "beginner's knowledge" about graphical user interfaces.
The hyperbook selects the best project(s) by comparing the weighted sums of these two measures. The weights allow to emphasize either one of the aspects matching and fitness. Currently, we emphasize matching. This will change if more projects with overlapping content are added to the hyperbook. For example, if we have four projects concerned with exception handling in Java, fitness will become more relevant to determine the project that introduces the relevant goal concepts tailored to the user's current knowledge state.
![]()
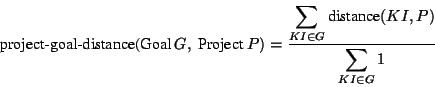 |
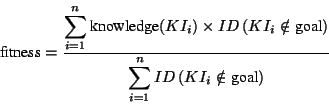 |
If a user wants more guidance during his learning he may ask the hyperbook for the next learning step. This request is resolved by determining a suitable learning goal depending on his current knowledge. Based on this goal, the hyperbook can propose a suitable project, a set of information units or a trail leading to that goal. To determine the next suitable learning goal, a sequential trail covering the whole hyperbook is calculated. For each item of this trail the system's estimate about the user's knowledge is checked - if the user fails to know some knowledge item, this item is proposed as the next suitable goal.
As discussed previously, the links between information units are based on their semantic relationships. Annotation of these links is very useful if a user just wants to browse through the hyperbook. Links are marked as "ready for reading" (green ball in front of a link), "not ready for reading" (red ball) or "already known" (grey ball) to help the user select appropriate information units.
The technique of indexing every page with concepts learned by reading a page, prerequisite knowledge and, in addition, the prerequisite that makes this page superfluous, is also used by [5]. The authoring tool provided in Interbook [4,3], which evolved from the ELM-ART tutoring system, uses a hierarchically organized domain model based on texts structured with sections, subsections, etc. Based on this domain model, pages of the electronic textbook are generated. Pop [12] uses a hierarchy for knowledge representation. These approaches of using an explicit domain model are similar to our approach, but we allow generally structured domain models based (e.g. based on the description of a software engineering process ("process", "phases", "activities")). PT [14] uses three levels for a customized hypertext: A domain representation level, stereotypes and an individual model. A meta hypertext is used to cover examples of different sorts (mathematical, text-based, tiny-focussed, larger-complete) thus this meta model has a different role as the meta model used in our hyperbooks as it handles pages with different attributes. The used implementation technique (e.g. preprocessor commands) is very different from our approach and handles page adaption. The use of knowledge components for structuring the domain is very similar to the way we model the conditional dependencies for our BN: more general concepts are splitted into refined concepts which themselves may be splitted into refined concepts, etc.
A comprehensive review of current work in using uncertainty management techniques in user modeling is given in [13]. Systems using Bayesian networks are for example [1,6] that employ BNs for plan recognition and coached problem solving. EPI-UMOD [17] uses separate BNs for each of a number of concrete user categories in which special conditional dependencies between knowledge items for each stereotype are implemented. POKS [7] constructs a network of implication relations among knowledge units from a small sample of user data sets. The use of BNs in our hyperbook is distinct from these approaches. We use a single, overall dependency graph for modeling the knowledge of the application domain. Clearly, this graph is not as fine grained as a graph that is suited for e.g. plan recognition as it serves different purposes. The BN used for our user model has to model dependencies among knowledge units which describe the application domain. User model and domain model are required to implement a hyperbooks. In addition, as we use a three-level model for finding dependencies among the knowledge units and a clustering mechanism for generating an acyclic graph, we implemented an exact inferring alg>rithm as proposed in [16]. Dynamic Bayesian networks are used in [18]. As we implement goal-driven learning, we have no time critical tasks (time-critical in the sense of Dynamic BNs). But we see a requirement in learning our BN out of data. This will be important as we use one overall Bayesian network for modeling the different users of our hyperbook that could be improved by learning strategies for BNs (see UAI).