 |
Anna Stefani and Carlo Strapparava
Istituto per la Ricerca Scientifica e Tecnologica,
I-38050 Povo/Trento, Italy
e-mail: {stefani | strappa}@irst.itc.it
Abstract: SiteIF is a personal agent that takes into account the user's browsing "watching over the user's shoulder". It learns user's interests from the requested pages that are analyzed generating or updating a model of the user. Exploiting the user model, the system tries to anticipate what documents in the web site could be interesting for the user. The system interactively and incrementally learns about the user's areas of interest generating/updating a user's model.In this paper we present some developments of SiteIF that take advantage of some natural language processing (NLP) techniques in building the user model. In particular we describe a module that use WordNet hierarchy to make more meaningful the semantic network that represents the user's interest.
Keywords: Internet, Adaptive System, User Modeling, Information Filtering, WordNet.
More information become available on the Web, more difficult it becomes to search for information, especially for novice users. It is important to build tools that not only help users satisfy their information needs, but also that promote new documents that are potentially interesting for the users.
However, information preferences vary greatly across users and filtering systems must be highly personalized to serve the individual interests of the user. This implies that the system has to be able to recognize the users and to maintain a model for their interests. This is valuable both from a user point of view and from the web sites maintainers: especially in the field of electronic commerce knowing personal interest of the customers allows the exploitation of the one-to-one marketing paradigm [Peppers & Rogers, 1997].
Several tools have been proposed to search and retrieve relevant documents ([Lieberman, 1995], [Armstrong et al., 1995], [Kamba & Sakagami, 1997], [Minio & Tasso, 1996]). Anyway all these systems share some basic limitations: the technique used to represent a user's profile is based on simple lists of keywords (and single words are often not enough to describe someone's interests) and the learning method requires the users' conscious and active involvement filling a form of keywords (topics) for their interests or adding a score to each visited document. Another common limitation is that the representation of user's interest is built without considering word sense disambiguation, but only taking into account, for example word frequency, words co-occurrence and so on. This yields a representation that is often not enough accurate from a meaning point of view. The issue is even more important in the Web world, where the documents could have to do with many different topics and the chance to misinterpret word sense is a real problem. The use of natural language analysis should be a solution, but in the web domains (many subjects, large lexicon etc...) classical fine-grained NLP techniques (such as parsing, semantic/pragmatic analysis etc...) could be often discouraged or unrealistic.
However the availability of word sense repositories, such as WordNet [Miller, 1990], increased the interest for the realization of concrete NLP applications that can take advantage of sense distinctions. WordNet makes a great number of fine-grained word sense distinctions. However, what could be seen as an advantage has often been considered a problem from a computational point of view. A great number of sense distinctions makes harder the problem of word sense disambiguation [Artale et. al., 1998].
This paper describes a development of user model component of SiteIF system that take into account the possibility to disambiguate word senses using WordNet hierarchy. We use a measure of semantic similarity in a is-a taxonomy very much like that described in [Resnik, 1995]. The idea is to build a semantic network whose nodes represent not simply the word frequency but the word sense frequency.
This approach takes advantages of MultiWordnet project on work at IRST [Artale et. al., 1997], that considers the problem to extend the WordNet hierarchy for other languages (in particular for Italian). This makes possible to build a user interest model independent from the language of the documents passed over by the user. This is particular important with multilingual web sites, that are becoming very common especially in electronic commerce domains.
Section 2 gives an overview of SiteIF functionality and structure. In section 3 we address the use of WordNet hierarchy in building and maintaining the user model exploiting a notion of semantic similarity.
2. A short overview of the SiteIF
System
SiteIF [Stefani & Strapparava, 1998] is a personal agent that follows the users from page to page as they browse a web site. It learns user's interests from the requested pages that are analyzed to generate or update a model of the user.
This model is represented using a semantic net developed similarly to IFTool system [Minio & Tasso, 1996]. However, unlike from IFTool, SiteIF avoids involving the user in its learning process (it does not ask the user for any keywords or opinions about pages) and only takes into account the addresses of the visited pages. In this way it is possible to give advices about pages and documents of the web site that SiteIF supposes could be interesting for the user.
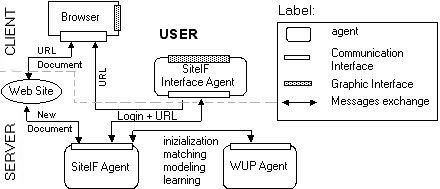
Figure 1 shows the SiteIF architecture which includes the following modules:
SiteIF Interface Agent: it controls the graphic interface and manages the interaction operations with the user.
SiteIF Agent: it yields the function of writing and generating personal documents based on the user's interests.
Wup Agent: it implements the main functions of the system: it helps retrieve and select the documents useful for the user, inside the web site.
Browser: it controls the interaction
operations of the user about the normal navigation on the Internet and
shows documents and results.
|
Figure 1 - Functional architecture of SiteIF
User can interact through two graphic interfaces: the first is controlled by the SiteIF Interface Agent, the second is the browser itself. The SiteIF Agent is called by the SiteIF Interface Agent that sends a request of identification/authentication and, once verified, it allows the user to enter the web site. The SiteIF Interface Agent follows and monitors the actions of the user inside the site. Every time he/she follows a link, the selected URL is sent to the SiteIF Agent while the Netscape window displays the requested document. The SiteIF Agent records all the browsed documents in a log file.
The log file is sent to the Wup Agent that initializes or updates the
user model. After the modeling phase, the Wup agent filters the documents
of the site according to the user model built before and sends back the
results to the SiteIF Agent. Every agent has a quite complex architecture
that can be divided in other sub-agents or modules. In this paper we focus
on Wup Agent (that creates and maintains the user model). For more details
about other components of the system see [Stefani & Strapparava, 1998].
3. The use of WordNet in the Wup
Agent
The WUP (Web User Profiling) agent implements the following
steps: the user modeling, the comparison of the internal representation
of the document with the user model and, on the basis of the obtained results,
the classification of the document (i.e. interesting or not interesting).
In previous version of SiteIF the user model was represented using a semantic
net developed similarly to IFTool system [Minio & Tasso, 1996]. Every
node was a word and the arcs between nodes were the co-occurrence relation
of two words; every node and every arc had a weight (that represents a
different level of interest for the user). That approach, although comparable
with those used in other current systems, was not accurate enough to discriminate
word meanings. The WUP Agent presented here yields the user model as a
synset net.
3.1 WordNet and a measure of semantic similarity
WordNet is a lexical knowledge base for English, available at no charge. Originally the project was inspired by the current psycholinguistic theory of human lexical memory. Nouns, verbs, adjectives and adverbs are organized in sets of synonyms (synsets), each of which represents a concept. These sets of synonyms are interconnected by a certain number of relations (is-a, part-of, etc...) and organized into taxonomies. The current version of WordNet includes about 100,000 lexical items (word forms) organized into 80,000 meanings (or synsets). The correspondence among lexical forms and meanings is maintained through a bi-dimensional matrix in which each synset is understood to be an unambiguous designator of the meaning of the word.
SiteIF takes advantages of a multilingual WordNet
under development at IRST. The starting point for building a WordNet multilingual
network is based on the assumption that the meaning networks already defined
for the original English version may, for the most part, be reused for
other languages. This may be considered plausible if we limit ourselves
to the main indoeuropean languages, among which there is much cultural
overlap [Miller -- personal communication].
|
"list-of-parents", "list-of-children" } |
Figure 2 - An example of multilingual sysnset
It is possible to introduce a notion of semantic similarity in WordNet is-a taxonomy (see for example [Resnik, 1995]). The idea is to associate probabilities with synsets using noun frequencies from large corpora. Each synset S (that represents a concept) is augmented with a probability function pr(S) that gives the probability of encountering an instance of concept S. The probability function has the following property: if S1 is-a S2 then pr(S1) £ pr(S2). The probability of the root is 1. Following the usual argumentation of information theory, the information content of a concept S can be represented as the negative logarithm of its probability (i.e. log pr(S) ). The more abstract is a concept, the lower is its information content. The root of the hierarchy has information content 0.
Given two polysemous words (i.e. the list of synsets which the words belong to), the algorithm for their sense disambiguation is based on the fact that their most informative subsumer provides information about which sense of each word is the relevant one. This method can be generalized for a group of words, considering the words pairwise.
3.2 User Model
A document representation module analyses the site documents and produces their internal representations, constituted by a list of synsets. In particular, this is made through standard techniques (such as segmentation, stop list deletion, stemming and weighting) [Salton & McGill, 1983], a specific algorithm which is devoted to identify the best terms to represent the content of a document (compression) [Asnicar & Tasso, 1997], and an application of sense disambiguation algorithm described above.
During the modelling phase (SiteIF considers the browsed documents during a navigation session), the Wup Agent yields (i.e. builds or augments) the user model as a semantic net whose nodes are synsets (concepts) and arcs between nodes are the co-occurrence relation of two concepts; every node and every arc has a weight (that represents a different level of interest for the user). The weights of the net are periodically reconsidered and possibly lowered (depending on the time passed from the last update). Also no more useful nodes and arcs may be removed from the net. So it is possible to consider changes of the user's interests and to avoid that uninteresting concepts remain in the user model.
During the filtering phase, the system compares any document (i.e. any representation of the document in terms of synsets) in the site with the user model. A matching module receives as input the internal representation of a document and the current user model. It produces as output a classification of the document (i.e. it is worth or not the user's attention). The relevance of any single document is estimated using the Semantic Network Value Technique (see for details [Stefani & Strapparava, 1998], [Stefani, 1998]). The idea behind SiteIF algorithm consists of checking, for every concept in the representation of the document, whether the context in which it occurs has been already found in previously visited documents (i.e. already stored in the semantic net). This context is represented by the co-occurrence relationship, that is by the couples of concepts included in the document which have already co-occurred before in other documents (information represented by arcs of the semantic net).
Since the representation of user interest is made of synsets (and not of simple words), the relevant documents proposed to the user embody not just the "same" words as other visited documents, but the same concepts.
4. Conclusions and Future Work
From a structural point of view, reasoning on a net formed by (lexical) concepts has obvious advantages. For this reason we chose to use WordNet as large lexical knowledge base to improve the information filtering and to construct and maintain a user model as a synsets semantic network.
It would also be possible to introduce a notion of user model coherence using for example algorithms described in [Morris & Hirst, 1991]. This kind of methods could estimate how much the user model talks "about the same thing". So we plan to develop a module that use WordNet to infer dynamically the interest areas of the resulting user model (for the moment, in SiteIF, there are a fixed number of interest areas).
Another issue is that using the multilingual extension of WordNet developed at IRST, in which the synset structure is common and the single synsets are augmented with synonyms from other languages, it is possible to have a user model independent from the language of the documents browsed by the user.
For the moment we are using only the noun hierarchy
in the WordNet is-a taxonomy. We plan to extend our algorithms to take
advantages of both noun part-of hierarchy and verb hierarchy as soon as
possible.
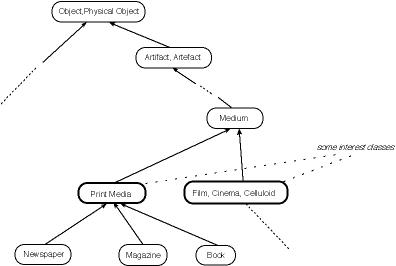 |
Figure 3 - A sketch of WordNet hierarchy with some synsets chosen as roots for interest classes.
References
[Artale et. al., 1997] Artale, A; Magnini, B; Strapparava, C.: "WordNet for Italian and its Use for Lexical Discrimination", in Lenzerini, M. (ed.) "AI*IA97: Advances in Artificial Intelligence", Springer Verlag, 1997.
[Artale et. al., 1998] Artale, A.; Goy A.; Magnini M.; Pianta E.; Strapparava C.: "Coping with WordNet Sense Proliferation", First International Conference on Language Resources and Evaluation, Granada, Spain, May 1998.
[Asnicar & Tasso, 1997] Asnicar, F.; Tasso, C.: "ifWeb: a Prototype of user models based intelligent agent for document filtering and navigation in the world wide web", Sixth International Conference on User Modeling, Chia Laguna, Sardinia, Italy, 2-5 June 1997.
Rif.: http://www.dimi.uniud.it/~ift/um97/positionp.html
[Kamba & Sakagami, 1997] Kamba, T.; Sakagami, H.: "Learning Personal Preferences on online Newspaper articles from user behaviors", Sixth International World Wide Web Conference Proceedings, 1997.
Rif.: http://atlanta.cs.nchu.edu.tw/www/PAPER142-2.html
[Lieberman, 1995] Lieberman, H.: "Letizia: An Agent That Assists Web Browsing", Proceedings of the 1995 International Joint Conference on Artificial Intelligent, Montreal, Canada, August 1995.
Rif.: http://lieber.www.media.mit.edu/people/lieber/Lieberary/Letizia/Letizia.html
[Minio & Tasso, 1996] Minio, M.; Tasso, C.: "User Modeling for Information Filtering on INTERNET Services: Exploiting an Extended Version of the UMT Shell", Workshop on User Modeling for Information Filtering on the World Wide Web, in Proceedings of the Fifth International Conference on User Modeling, Kailia-Kuna Hawaii, January 1996.
Rif.: http://www.cs.su.oz.au/~bob/um96-workshop.html
[Miller, 1990] Miller, G.: "An On-Line Lexical Database" International Journal of Lexicography, 13(4), pp.235-312, 1990.
[Morris & Hirst] Morris, J.; Hirst, G.: "Lexical Cohesion Computed by Thesaural Relations as an Indicator of the Structure of Text", Computational Linguistics, 17(1), 1991.
[Peppers & Rogers, 1997] Peppers, D.; Rogers, M.: "The One to One Future: Building Relationships One Customer at a time", Currency Doubleday, 1997.
[Resnik, 1995] Resnik, P.: "Disambiguating Noun Groupings with Respect to WordNet Senses", Third workshop on very large corpora, MIT, June 1995.
[Salton & McGill, 1983] Salton, G.; McGill, M.H.: "Introduction to modern information retrieval", McGraw-Hill, New York, 1983.
[Stefani, 1998] Stefani, A. "Determinazione automatica del profilo utente Web per applicazioni di marketing". Thesis, University of Trento, 1998
[Stefani & Strapparava, 1998] Stefani, A.; Strapparava, C: "Personaliziong Access to Web Sites: The SiteIF Project", 2nd Workshop on Adaptive Hypertext and Hypermedia (held in conjunction with HYPERTEXT '98), Pittsburgh, USA, June 1998.
[Stefani & Strapparava, 1998] Stefani, A.; Strapparava, C.: "Determinazione automatica del profilo dell'utente Web: il sistema SiteIF", Sesto convegno dell'Associazione Italiana per l'Intelligenza Artificiale, Padua, Italy, September 1998