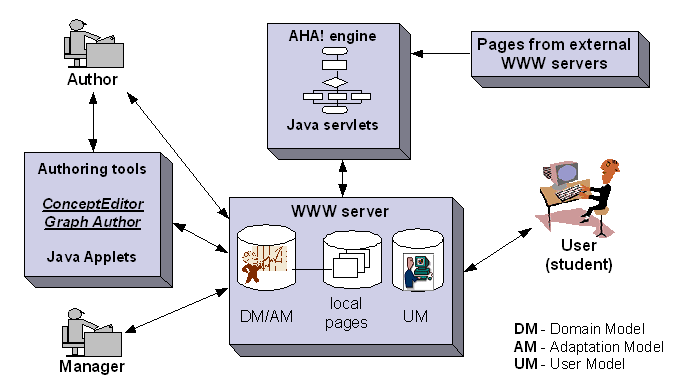
Figure 1. Overall architecture of the AHA! system

Contents |
Hypertext, and the Web in particular, offers three ways to find information:
The community of user modeling and adaptive hypermedia offers solutions for this problem: using information gathered about the user during the browsing process to change the information content and link structure on-the-fly. User modeling captures the mental state of the user, and thus allows that knowledge to be combined with the explicit queries (or links) in order to determine precisely what the user is looking for. To support the design of this user model-based adaptation, reference models like AHAM (De Bra et al. 1999, Wu 2002) and Munich (Koch and Wirsing 2002), both based on the Dexter Model by Halasz and Schwartz (1994), have been introduced in an attempt to standardize and unify the design of adaptive hypermedia applications, used mostly in isolated information spaces such as an online course, an electronic shopping site, an online museum, etc.
To become "The Next Big Thing", adaptive hypermedia systems need to open their architecture to allow collaboration between sites to provide better adaptation than is currently possible. The latest developments within the scope of the Semantic Web are leading adaptive hypermedia towards the "Adaptive Web" of semantically organized information in concept structures, where collaborative Web services allow for the encapsulation of the diverse knowledge, for the modularization of the architecture, and for a more dynamic and sharable framework for automated personalization or adaptation. In this way, current adaptive hypermedia architectures will be extended with powerful reasoning at the level of standardized concept schemes, as opposed to the traditional hand-crafting by authors of the domain concept relations, thus allowing adaptation generation in open information spaces on a higher schema level.
This paper first briefly recalls and summarizes the overall architecture of (Web-based) adaptive hypermedia systems (AHSs) to show how to extend and modularize this architecture to enable different AHSs to work together at different levels: the conceptual structure, the user models, and the adaptation. Last but not least, we point out some legal problems that arise as a consequence of opening the user model to be shared among various applications, which is technically possible but maybe legally unacceptable in the improved adaptive hypermedia architecture we propose.
Figure 1 shows that the three submodels (DM, UM, AM) all reside on a central Web server, together with the "local pages" (content fragments). In AHA! the engine handles page requests. (Pages can come from external servers, but the corresponding concepts must exist in the local domain model.) Each page request results in updates to the user model. That user model is used to perform the adaptation.
The centralized architecture of AHA! (and several other systems) has the advantage that the DM, AM and UM can work closely together. A typical optimization is to retrieve the DM and AM when the server starts, and the UM when the user logs on, and to keep all that information cached in memory, periodically saving the updates to UM to disk (or database). For adaptive systems to work together, as suggested in the introduction, a new, decentralized and modular architecture is needed, as will be presented in Figure 2. The issue of optimization is transferred towards the bridging protocols and the information request coordination between the DM, AM and UM in that architecture. We recognize that performance remains very important as a key to the success of adaptive information services in that they should be (nearly) as performant as non-adaptive services.
Apart from the issue of collaboration between adaptive systems, the centralized architecture has some other drawbacks: the semantic information about the application domain is usually stored inside a local domain and adaptation model. Relationships between concepts are "hidden" inside adaptation rules (although some AHSs provide a graphical interface - i.e. Graph Author in AHA!, Figure 1 - for the authors to define the concepts and relationships and make high-level relationships plainly visible). It is difficult to "export" the semantic information contained in the DM/AM combination to applications that deal with concepts and relationships in another way. It is equally difficult to "import" semantic information, e.g. an ontology, into an AHA! application. Also, the user model cannot be accessed by external applications. It is only shared by applications running on the same AHA! server. Knowledge gained by the user through an online course cannot be used by an online course at another institute or department in order to initialize the user model there.
The next section looks at various research efforts attempting to provide solutions for these problems while facilitating adaptation to various users navigating a diverse and distributed open information space. Methods are proposed to improve the quality, consistency and linking of Web documents while the user is browsing, and for the authors when creating the adaptation. Reflecting on this work we propose a new, modular architecture of an open Web-based adaptive system that overcomes the above difficulties.
The essence of ubiquitous computing is to offer to users systems with "invisible" (ambient) intelligence, which will be able to know about the user and offer him/her the desired service, content and presentation, without intrusion and unnecessary human computer interaction. Adaptation across applications, seen as the "Next Big Thing" and realized with the notion of adaptive Web-based systems, defines the goal today: to provide adaptation within software environments, where the users are able to interact simultaneously with various applications. For this we need open and modularized architectures, which are able to interact, exchange data, and share components. A fundamental issue in such architectures relates to the coordination, handling and control of all the components (services) within them. One of the biggest challenges in this context is the sharing, synchronization and interpretation of the user model among the different applications. This way the user behavior within each system will be permanently evaluated and more detailed, and richer user models will be achieved in order to allow for enriched adaptation and personalization of the content. This paper presents our approach for achieving this openness and modularity of the adaptive hypermedia system architecture. To enable different AHSs to work together at different levels (e.g. conceptual, user model, and adaptation) we see the need for four main aspects:
Currently research in the area of the Semantic Web, originating primarily from the knowledge engineering and artificial intelligence fields, with a special focus on ontologies and Web services, provides a number of standards and accompanying solutions which can be used to achieve the above-mentioned requirements. On the one hand we have the notion of ontology, which plays a role in facilitating the sharing of meaning and semantics of information between different software entities. A number of representational formats have been proposed as W3C standards for ontology and metadata representation. The most current advances with OWL exploit existing Web standards (e.g. XML, RDF and RDFS) and add the primitives of description logic as powerful means for reasoning services. One of the earliest research initiatives to illustrate this is the SHOE metadata annotation of Web content (Heflin et al. 1999). The idea was further elaborated in the CREAM framework (Handschuh et al. 2001), with use of ontology concept instances, considering evolving ontologies and offering annotation in a semi-automated way.
Several other annotation tools are known to the research community, e.g. the Amaya Web editor for RDF-based mark-up of resources while being created. Annotea also points out the advantages of a centralized server, and its unapplicability in "open" environments. It exemplifies a good scenario for collaborating authoring agents within "closed" content spaces, and illustrates its difficult implementation in an "open" information space. Other examples of annotation systems are given by the Enrich project (Mulholland et al. 2000), the CREAM-based Ont-O-Mat/Annotizer (Handschuh et al. 2001), MnM (Vargas-Vera et al. 2002), Letizia (Lieberman 1995), etc.
As the annotation is only part of the content authoring, another rather labor-intensive part is the process of linking the annotated content. The Conceptual Open Hypermedia Services Environment (COHSE) developed by Carr et al. (2001) introduces an ontological reasoning service over domain concepts and their relationships in combination with a Web-based open hypermedia link service: this enables documents to be linked via metadata describing their contents in a conceptual hypermedia system. Another recent project inspired by COHSE and applying ontologies and semantic services for the automation of semantic content annotation is Magpie (Dzbor et al. 2003). This project facilitates various interpretation views on the same content with no prior mark-up, but by means of adding an ontology-derived semantic layer (see Domingue et al. 2004). On top of this semantic layer Magpie deploys semantic services provided to the user as a physically independent layer over a particular Web resource.
Thus, the next step in the process of opening up AHS architectures is applying a Web services perspective on the system components. Web services make use of the above-mentioned semantics and offer means for flexible composition of services (system components) through automatic selection, interoperation of existing services, verification of service properties, and execution monitoring. In an approach such as DAML-S/OWL-S (DAML) for example, the ProcessControl Ontology provides a process definition in terms of its state, initial activation, execution, and completion. The ServiceModel, on the other hand, provides a means for describing the data flow and the control flow in the case of a composite service, and the ServiceGrounding specifies the service access to information by communication protocols, transport mechanisms, etc.
Another relevant approach for describing the role of Web services in system architecture is the Web Service Modeling Framework (WSMF) by Fensel and Bussler (2002). That research shows that Web services appear to be a useful solution for achieving modularization. We can achieve reasonable automation and dynamic realization of the main aspects of Web services (e.g. Web service location, composition and mediation) by extending them with rich formal descriptions of their competence (in standardized languages such as RDF or OWL). In this way we can allow adaptive Web-based systems to reason about the functionalities provided by different Web services, to locate the best ones for solving a particular problem, and automatically to compose the relevant Web services for dynamic application building.
An interesting approach that could serve as the basis for a successful application of the Web service perspective on AHS architecture is given by an existing Web service framework like the Internet Reasoning Service (IRS-II) introduced by Motta et al. (2003). They show how we can support the publication, location, composition and execution of heterogeneous semantic-rich Web services. The service uses UPML (Unified Problem-solving Method description Language) to specify reusability in knowledge-based systems by defining how we can build elementary components and how these components can be integrated into one whole system, as described by Fensel et al. (1999). The IRS-II approach supports capability-driven service invocation (e.g. find a service that can solve problem X) because of the explicit separation of task specifications (the problems which need to be solved), method specifications (the ways to solve problems), and domain models (the context in which these problems need to be solved). This separation of system components actually fits quite nicely with the requirements for exploiting the Web service paradigm in the context of AHSs, as shown by Figure 2.
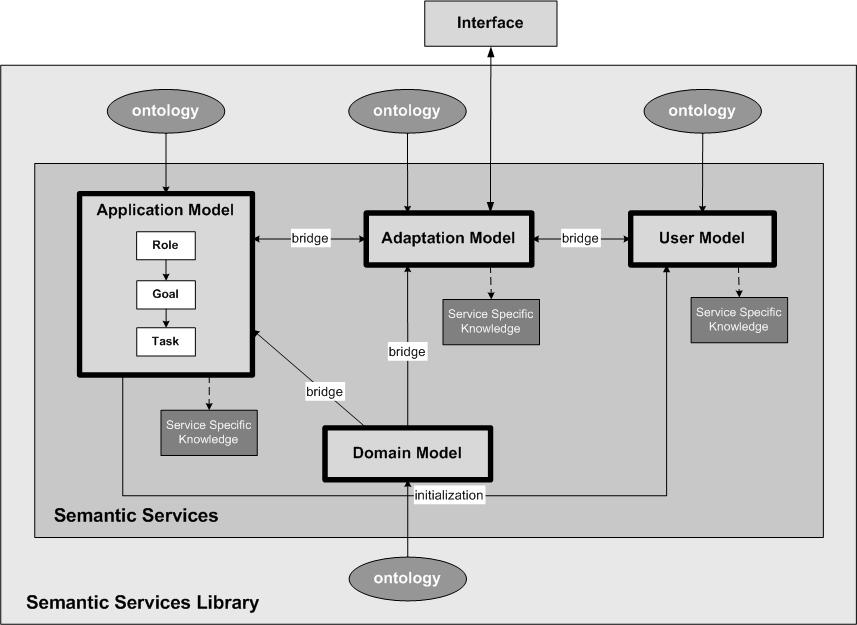
Figure 2 illustrates our vision of the modular architecture for adaptive Web-based systems (Chepegin et al. 2003). One of the first characteristic aspects we observe is that the different system components are all equipped with facilities to communicate with the (other) components in terms of service invocations. In this architecture, bridges are used in accordance with the UPML framework connector defined by Fensel et al. (1999), in order to specify mappings between the different model services within the architecture. Ontologies also play an important role to define and unify the system's terminology and properties to describe the knowledge of each system service. Each service can be specified by means of a corresponding ontology, providing common ground for knowledge sharing, exploitation and interoperability among the services. This leads to a highly modularized architecture which offers a high degree of flexibility.
In the case of adaptive systems access to the user model via a Web service is a good example of this flexibility. It means that designers can design systems that will interact with or react to the user intelligently without knowing anything in advance about that user, but simply using the knowledge collected by other applications and interpreting it in the context of the current application. Crucial for achieving such a flexible architecture is the need for a standardized protocol for encoding information about users. As mentioned above, open standards (e.g. XML, RDF, OWL) allow for the specification of ontologies to standardize and formalize meaning and to enable reuse and interoperability. Another key aspect is to facilitate mobile user models that follow the user across applications. Results in the field of software agents provide implementation views supporting mobility and autonomous behavior. A final but important requirement is for the user modeling system to be able to reuse system and knowledge components, and thus benefit from other applications.
A second characteristic seen in Figure 2 is the separation of the different components. In the traditional AHS approach, exemplified by AHAM, three submodels are distinguished (section 2). When transforming these components into services the need for a fourth component, the application model, emerges. The main reason for this lies in the fact that in the traditional AHS approach the adaptation model unites the actual process of how to adapt with the decisions why to adapt. In most applications, e.g. those realized in AHA!, the designer's knowledge about why the user is served in a certain way is more or less left implicit: the adaptation model implements the way in which the information is adapted to the user and does so based on the designer's decisions, which are not made explicit. In the situation where we want to share and exchange the different functionalities between systems, it becomes relevant to separate the "how" and "why" in the adaptation. While capturing the designer's intentions about the roles, goals and tasks in the application (related to domain model concepts and user model values), the adaptation model restricts itself to the actual realization of the adaptation to follow the directions given by the application model. In fact this aligns well with the proposal from the IRS-II approach, mentioned above. The application model service contains a generic description of the user tasks in the context of a Role-Goals-Tasks model.
It is clear that this gives the application model service a crucial role in the system architecture. It divides the adaptation process into two parts, where the actual technical adaptation is performed by the adaptation model service, while the management of the service process is coordinated from the application model service. The entire architecture as displayed in Figure 2 emphasizes the fact that the core knowledge about the application processes and the user activities (tasks, roles and goals) lies in the application model service. In the interaction with the application the user is represented by a particular role (e.g. guest, a system expert, administrator, student). This role defines for him/her a corresponding behavior in terms of goals to achieve. To accomplish the user's goals appropriate tools (applications) are used, which realize one or several corresponding methods. The adaptation model service receives the direct user input and interacts with the application model service in order to define the context for the user input for its most precise adaptation. Further the adaptation model service queries the domain model service in order to select the relevant content to be presented to the user. The domain model service is responsible for the explicit storage and description of the domain knowledge in terms of concepts of a domain ontology. Finally, it updates the user model with new values. For instance, when users work with a selected application, every action they perform on the user interface is communicated to the user model service, which is responsible for updating the user model with the new values. The user information is stored there and a reasoning engine infers new knowledge from it and makes predictions concerning future user behavior. In this way the user model service allows for sharability of the user model between applications by following the user (inside and outside the system) in order to collect and further analyze data about the user's activities.
The following section discusses some possible disadvantages and legal problems raised by this open modularized architecture with respect to the user model exchange and access by various collaborating parties.
Carr, L., Bechhofer, S., Goble, C. and Hall, W. (2001) "Conceptual Linking: Ontology-based Open Hypermedia". In Tenth International World Wide Web Conference, Hong Kong, May http://www10.org/cdrom/papers/246/
Brusilovsky, P. (2001) "Adaptive hypermedia". User Modeling and User Adapted Interaction, Ten Year Anniversary Issue, 11 (1/2), 87-110 http://www.sis.pitt.edu/~peterb/papers/brusilovsky-umuai-2001.pdf
Brusilovsky, P., Eklund, J. and Schwarz, E. (1998) "Web-based education for all: A tool for developing adaptive courseware". Proceedings of 7th International World Wide Web Conference, Brisbane, April http://www7.scu.edu.au/programme/fullpapers/1893/com1893.htm
Chepegin, V., Aroyo, L., De Bra, P. and Houben, G. (2003) "CHIME:
Service-oriented Framework for Adaptive Web-based Systems". In
Conferentie Informatiewetenschap, Eindhoven, November, pp. 29-36
http://wwwis.win.tue.nl/infwet03/proceedings/3/
De Bra, P., Aerts, A., Berden, B., de Lange, B., Rousseau, B., Santic, T., Smits, D. and Stash, N. (2003) "AHA! The Adaptive Hypermedia Architecture". In Proceedings of the fourteenth ACM conference on Hypertext and Hypermedia, Nottingham, August, pp. 81-84 http://wwwis.win.tue.nl/~debra/ht03/pp401-debra.pdf
De Bra, P., Aerts, A., Smits, D. and Stash, N. (2002) "AHA! The Next Generation". In Proceedings of the thirteenth ACM conference on Hypertext and Hypermedia, College Park, MD, June, pp. 21-22 http://wwwis.win.tue.nl/~debra/ht02.pdf
De Bra, P., Houben, G.-J. and Wu, H. (1999) "AHAM: A Dexter-based Reference Model for Adaptive Hypermedia". In Proceedings of the 10th ACM conference on Hypertext and Hypermedia, Darmstadt, February, pp. 147-156 http://citeseer.ist.psu.edu/debra99aham.html
Domingue, J., Dzbor, M. and Motta, E. (2004) "Semantic Layering with Magpie". Handbook on Ontologies, pp. 533-554 http://kmi.open.ac.uk/people/dzbor/public/2003/Dxx-Dom-Dz-Mo.pdf
Dzbor, M., Domingue, J. Motta, E. (2003) "Magpie - Towards a Semantic Web Browser". In Proceedings 2nd International Semantic Web Conference (ISWC2003), Lecture Notes in Computer Science 2870/2003 (Springer-Verlag), pp. 690-705 http://kmi.open.ac.uk/people/domingue/papers/magpie-iswc-03.pdf
Fensel, D. and Bussler, C. (2002) "The
Web Service Modeling Framework WSMF", white paper
http://informatik.uibk.ac.at/~c70385/wese/wsmf.paper.pdf
Fensel, D., Motta, E., Benjamins, V.R., Decker,
S., Gaspari, M., Groenboom, R., Grosso, W., Musen, M., Plaza, E., Schreiber,
G., Studer, R. and Wielinga, B. (1999) "The Unified Problem-Solving Method
Development Language UPML", ESPRIT project deliverable 1.1, chapter
1
http://www.swi.psy.uva.nl/projects/IBROW3/docs/deliverables/d1-1-ch1-upml.pdf
Halasz, F. and Schwartz, M. (1994) "The Dexter Hypertext Reference Model". Communications of the ACM, 37(2), 30-39
Handschuh, S., Staab, S. and Maedche, A. (2001) "Cream - creating relational metadata with a component-based, ontology-driven annotation framework". In Proceedings of the 1st International Conference on Knowledge Capture (ACM Press), pp. 76-83
Heckmann, D. and Kruger, A. (2003) "A User Modeling Markup Language (UserML) for Ubiquitous Computing". In 9th International Conference on User Modeling (UM'2003), Pittsburgh, June, pp. 393-397 http://www.dfki.de/~krueger/PDF/UM2003.pdf
Heflin, J., Hendler, J. and Luke, S. (1999) "SHOE: A Knowledge Representation Language for Internet Applications". Technical Report CS-TR-4078 (UMIACS TR-99-71), Dept. of Computer Science, University of Maryland at College Park http://www.cs.umd.edu/projects/plus/SHOE/pubs/techrpt99.pdf
Henze, N. and Nejdl, W. (2001) "Adaptation in open corpus hypermedia". International Journal of Artificial Intelligence in Education, 12 (4), Special Issue on Special Issue on Adaptive and Intelligent Web-based Educational Systems, 325-350
Kobsa, A. (2002) "Personalized Hypermedia and International Privacy". Communications of the ACM, 45(5), 64-67
Koch, N. and Wirsing, M. (2002) "The Munich Reference Model for Adaptive Hypermedia Applications". In 2nd International Conference on Adaptive Hypermedia and Adaptive Web-Based Systems, May , pp. 213-222
Lieberman, H. (1995) "Letizia: An Agent That Assists Web Browsing". International Joint Conference on Artificial Intelligence, Montreal, August http://lieber.www.media.mit.edu/people/lieber/Lieberary/Letizia/Letizia-AAAI/Letizia.html
Motta, E., Domingue, J., Cabral, L. and Gaspari, M. (2003) "IRS-II: A framework and Infrastructure for Semantic Web Services". In 2nd International Semantic Web Conference 2003 (ISWC 2003), Florida, October http://www.cs.unibo.it/~gaspari/www/iswc03.pdf
Mulholland, P., Domingue, J., Zdrahal, Z. and Hatala, M. (2000) "Organisational Learning: An Overview of the Enrich Approach". Journal of Information Services and Use, 20 (1), 9-23
Nielsen, J. (1990) Hypertext and Hypermedia (Academic Press)
Sullivan, D. (2003) "Search Engine Sizes". Search Engine Watch, September 2 http://searchenginewatch.com/reports/article.php/2156481
Vargas-Vera, M., Motta, E., Domingue, J., et al. (2002) "MnM: Ontology Driven Semi-Automatic and Automatic Support for Semantic Markup". In Proceedings of the 13th European Knowledge Acquisition Workshop (EKAW) http://kmi.open.ac.uk/projects/akt/publication-pdf/vargas-vera-etal.pdf
Weber, G. and Brusilovsky, P. (2001) "ELM-ART: An adaptive versatile system for Web-based instruction". International Journal of Artificial Intelligence in Education, 12 (4), Special Issue on Adaptive and Intelligent Web-based Educational Systems, 351-384 http://www.sis.pitt.edu/~peterb/papers/JAIEDFinal.pdf
Weber, G., Kuhl, H.C. and Weibelzahl, S. (2001) "Developing adaptive internet based courses with the authoring system NetCoach". Proceedings of the Third International Workshop on Adaptive Hypermedia, Sonthofen, Germany, July http://wwwis.win.tue.nl/ah2001/papers/GWeber-UM01.pdf
Weiser, M. and Brown, J.S. (1996) "Designing Calm Technology". PowerGrid Journal, Vol. 1.01, July
Wu, H. (2002) "A Reference Architecture for Adaptive Hypermedia Applications", PhD thesis, Eindhoven University of Technology, November http://wwwis.win.tue.nl/ah/thesis/wu.pdf
Annotea http://www.w3.org/2001/Annotea/
CERT Advisory CA-1993-15 /usr/lib/sendmail, /bin/tar, and /dev/audio Vulnerabilities, October 21, 1993; revised September 19, 1997 http://www.cert.org/advisories/CA-1993-15.html
DAML Services http://www.daml.org/services/