Vóór de komst van snelle netwerken bestonden informatiebronnen veelal uit databases van teksten en specifiek hiervoor ontwikkelde zoekprogramma's. In vele gevallen werden opzoekingen niet door de domein-expert uitgevoerd, maar door informatici, die complexe cryptische syntaxen konden beheersen, en de betekenis van Booleaanse logische expressies konden doorgronden.
Het onderzoeks- en ontwikkelingsgebied van de information retrieval evolueerde bijna tot een tak van sport, met de TREC wedstrijd als hoogtepunt. De vele deelnemers aan deze wedstrijden kunnen ruwweg worden onderverdeeld in twee kampen:
De uitvinding van de CD-ROM heeft het mogelijk gemaakt grote databases met teksten en multimedia informatie tot op elke werkplek en tot in de huiskamer te brengen. Het zilveren schijfje, door Philips ontwikkeld om een uurtje muziek te kunnen afspelen, kan meer tekst bevatten dan een mens in één maand tijd kan lezen, en ook meer tekst dan vele mainframe computers van slechts enkele jaren geleden konden opslaan en verwerken. De grootste uitdaging van de CD-ROM is echter niet de techniek van de data opslag en het opvragen van informatie. De CD-ROM op de werkplek en in de huiskamer betekent dat de domein-expert, de eindgebruiker en zelfs Jan met de PC in staat moeten zijn om in een grote tekst-database informatie op te zoeken zonder alles te moeten lezen.
Het gebruik van zoekmachines door eindgebruikers heeft de wereld van de information retrieval grondig door elkaar geschud. Het onderzoeksveld had zich altijd geconcentreerd op technieken om nauwkeurig gestelde vragen zo goed mogelijk te beantwoorden door relevante documenten te selecteren. Het was daarbij niet belangrijk dat vragen op een eenvoudige wijze konden worden gesteld. Om voor eindgebruikers geschikt te zijn moesten nieuwe methoden worden bedacht om vragen op een intuïtieve wijze te stellen, bijvoorbeeld door alleen maar een paar kernwoorden te geven. In de information retrieval is men inmiddels zover gevorderd dat een goede selectie van relevante documenten mogelijk is wanneer de gebruiker ongeveer 20 kernwoorden geeft, waarvan de meeste, maar niet noodzakelijk alle woorden in de gevonden documenten voorkomen.
De komst van Internet, en meer specifiek van World Wide Web, heeft andermaal een revolutie veroorzaakt in de information retrieval. Daar waar de informatie op een CD-ROM gemakkelijk te benaderen is, en geconcentreerd in één database, zijn de documenten in World Wide Web over de hele wereld verspreid, niet gecatalogiseerd, en ook nog eens moeilijk bereikbaar door de onbetrouwbare werking van vele computers die de informatie bevatten en door de zeer wisselende snelheid en betrouwbaarheid van Internet.
World Wide Web bestaat uit een zeer groot aantal documenten, meestal teksten en illustraties, die met elkaar verbonden zijn door middel van hypertekst links. Die links zijn aktieve verwijzingen tussen documenten. Ze kunnen het best vergeleken worden met een literatuurverwijzing, maar dan zo dat wanneer je met behulp van de computermuis de link aanklikt de verwijzing wordt gevolgd en het betreffende artikel op het scherm verschijnt, ook al staat dit op een computer aan het andere eind van de wereld. Dit hypertekst mechanisme is de grote kracht van World Wide Web, maar tegelijk ook de belangrijkste zwakte:
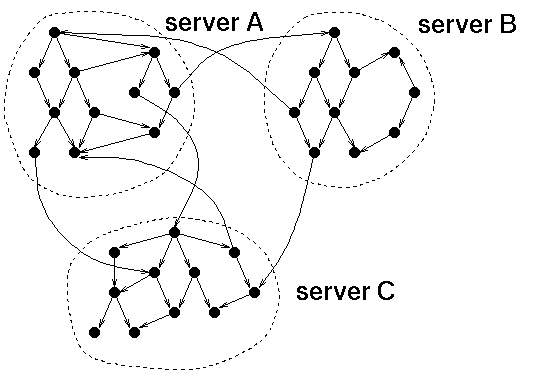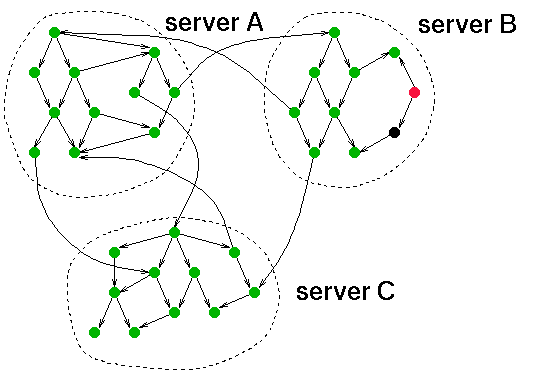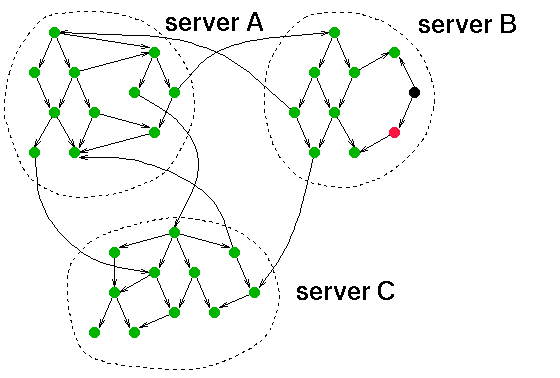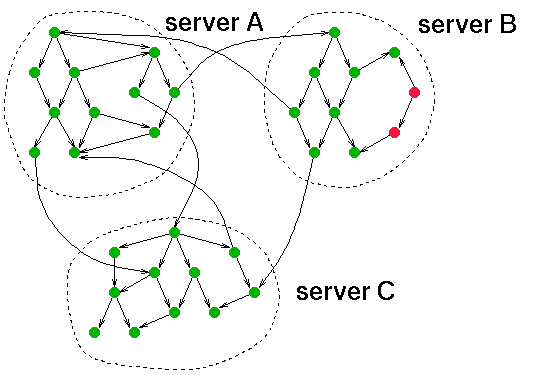
Uit het voorgaande zal duidelijk zijn dat het "eventjes" doorzoeken van het Web niet mogelijk is. Om in het hele Web op zoek te gaan naar bepaalde informatie moeten de documenten op voorhand op één plaats, of op een klein aantal plaatsen worden verzameld. De technologie die hiervoor ontwikkeld wordt bestaat uit robots of spiders. Een robot of spider is een computerprogramma dat automatisch Web-pagina's ophaalt voor "lokale" verwerking. Hij doet dit op dezelfde wijze als een menselijke gebruiker: door de links te volgen die in de Web-pagina's voorkomen. De robot doet dit natuurlijk veel sneller dan een mens, en op één enkele computer kunnen gemakkelijk 10 of meer robots tegelijk aan het werk gaan, om nog sneller het hele Web af te zoeken.
De documenten van het Web, verzameld door een robot, kunnen helaas niet zomaar letterlijk op de harde schijf van een computer of op een stel CD-ROMs worden opgeslagen. Met zijn circa 100 Gigabyte is het Web hiervoor veel te groot, en dit is alleen nog maar de tekstuele informatie, dus zonder de illustraties, video's en geluidsfragmenten. De informatie wordt opgeslagen in zogenaamde index-databases, die de informatie niet alleen veel compacter opslaan, maar ze ook veel efficiënter kunnen doorzoeken.
Voor de eindgebruiker is het begrip "index-database" niet zo interessant. De database wordt gebruikt om informatie te vinden in de vorm van relevante Web-pagina's. Daarom gebruikt men meer de al eerder genoemde term zoekmachine dan "index-database". Hoewel de zoekmachines voor het Web in principe hetzelfde werk doen als de oudste tekst-databases uit de information-retrieval wereld hebben ze het op een aantal punten veel moeilijker:
De meeste zoekmachines gaan voorbij aan de belangrijkste eigenschap die de hypertekst-technologie heeft toegevoegd aan de tekst-databases van vroeger: de aanwezigheid van links tussen documenten. Auteurs van documenten brengen links aan naar andere informatie, van henzelf of van anderen, omdat ze menen dat er een verband is tussen de pagina's die ze met elkaar verbinden. Deze verbanden kunnen worden gebruikt om nog beter te bepalen wat het onderwerp van een document is. Maar deze links kunnen nog voor iets heel anders worden gebruikt: om met beperkte middelen een robot in korte tijd pagina's te laten vinden over een onderwerp waarover men reeds enkele pagina's gevonden heeft. Deze methode wordt gebruikt door de Fish-Search robot [DBP94a,DBP94b,DBHKP94], die de motor is van het FishNet hulpmiddel [DBL97] voor Webpagina onderhoud.
Op het Web zijn veel "professionele" home pagina's te vinden, die grote aantallen links bevatten naar documenten over één bepaald onderwerp. Over zo'n onderwerp zijn er vaak verschillende dergelijke pagina's, die ook naar elkaar verwijzen.
Een typisch voorbeeld is de Adaptive Hypertext and Hypermedia home pagina. Deze pagina bevat verwijzingen naar de meeste onderzoekers die op dit gebied werkzaam zijn, naar conferenties en workshops, naar onderzoeksprojecten, en naar tijdschriften en on-line publicaties.Nieuwe documenten over dat onderwerp zijn gemakkelijk te bereiken door vanaf die professionele home pagina's links te volgen. De Fish-Search robot is precies bedoeld om vanuit zo'n home pagina gedurende een korte tijd op zoek te gaan naar nieuwe documenten over het onderwerp van de home pagina. Het FishNet tool gebruikt de Fish-Search om 's nachts nieuwe documenten op te zoeken en ter evaluatie aan de gebruiker voor te leggen. Wanneer er op het Web 100 pagina's staan over een zeer specialistisch onderwerp, dan lijkt het statistisch zeer onwaarschijnlijk dat een robot een pagina over dit onderwerp zou tegenkomen, als hij slechts een beperkte tijd heeft en dus ten hoogste een duizendtal pagina's kan bekijken. De praktijk toont echter dat wanneer eenmaal een relevante pagina is gevonden, een robot als de Fish-Search in zeer korte tijd de meeste andere pagina's over dat onderwerp wel degelijk kan vinden. De wijze waarop hypertekst links in het Web gebruikt worden toont aan dat de verdeling van documenten en onderwerpen in het geheel niet willekeurig is.